历史笔记迁移系列
Word转markdown真的好累
第一集:优化算法の笔记(上)- First Order Methods
第二集:优化算法の笔记(中) - Duality Method & Second Order Methods
第三集:优化算法の笔记(下) - ADMM & Coordinate Descent
0x02 Duality Method
0x02_1. Duality in Linear Programs and General Form
事物都有两面性,给定一个标准的凸优化问题,我们希望去构造一个点序列,通过不断的进行迭代,以逼近最小值。然而我们也可以想办法找出原问题的一个下界,然后不断的提升这个下界,以逼近最优值,这和EM算法的思想有一点相似,而对偶(Duality)问题就是基于这样的一个想法。下面以一些具体的例子进行入手。给定下面这个优化问题
\[\min_{x,y} x+3y\\ s.t. x+y \ge 2\\ \quad x,y\ge 0\] 那么,$x+3y$的下界是什么?当然是2,因为$x+3y=(x+y)+(2y)≥2$,所以Lower Bound是2,这个问题很简单,让我们在看一个更一般的例子,给定下面这个优化问题
\[\min_{x,y} px+qy \quad where \quad p,q \ge 0\\ s.t. x+y \ge 2\\ \quad x,y\ge 0\] 现在,我们令$a+b=p,a+c=q$, $a,b,c≥0$ ,那么我们有$px+qy=(a+b)x+(a+c)y \ge 2a$。事实上,现在我们这个方法得到的下界2a,比上一个例子的方法得到的下界(2p或者2q,取决于p,q的大小)更加松弛,但是这也并不太影响,我们只需要不断地提升这个下界2a,我们把问题转化成下式(右)。原问题A就转化成了一个对偶问题B
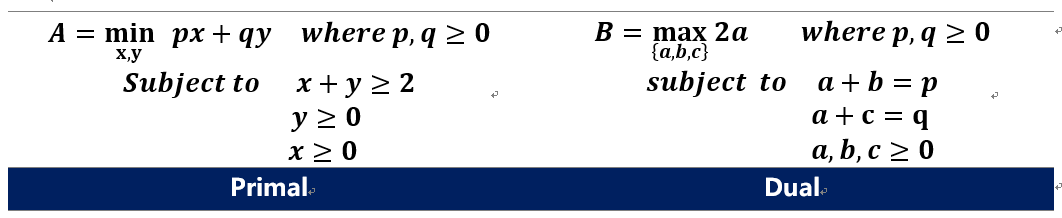
我们可以得到以下的性质
- 值$A \ge B$,即对偶问题的解一定是原问题解的一个下界,具体的证明将在后面说明
- 对偶问题的变量个数 等于 原问题的约束个数(包括等式约束与不等式约束)
- 对偶问题的不等式约束个数 等于 原问题不等式约束个数
- 如果两个问题的最优值满足A=B,则称他们是强对偶的(Strong Duality),否则他们的差称为Duality Gap
那么对于一般的问题来说,如何求得所对应的对偶问题呢?这个回答当然是Lagrange Duality,这也是比较常用的方法。给定下式原问题,其中$c\in R^{n}, A \in R^{m,n}, b\in R^{m}, G\in R^{r,n}$
\[A = \min_{x \in R^{n}} c^Tx\\ s.t. \quad Ax=b\\ \quad Gx \le h\] 首先构造他的拉格朗日乘子$L(x,u,v)=c^{T}x+u(Ax-b)+v(Gx-h)$,这里的$v,u$满足$v\ge 0$,若$x_{0}$是满足原问题约束条件的可行点,则必有下式成立
\[c^Tx_0 \ge L(x_0,u,v) = c^Tx_0 + \underset{等于零}{u(Ax_0-b)} + \underset{小于零}{v(Gx_0-h)} \ge \min_x L(x,u,v) = L(u,v)\] 也就是说,通过拉格朗日法构造出来的$L(u,v)$一定是原问题的下界,如果我们用$x^*$来表示最优解,那么有下式成立。
\[c^Tx^* \ge L(x^*,u,v) \ge \min_x L(x,u,v) = L(u,v)\]我们把它形式化成对偶的样子,先把拉格朗日乘子合并同类项一下,然后对$x$求min
\[L(x,u,v)=(A^Tu+c+G^Tv)x - b^Tu-h^Tv\\ L(u,v) = \min_x L(x,u,v) = \left\{\begin{matrix} -b^Tu-h^Tv \quad if \quad c=-A^Tu-G^Tv \\ -\infty \quad otherwise \end{matrix}\right.\]得到对偶问题,其中$u\in R^{m},v \in R^{r}$。注意这里是max,因为我们要提升下界
\[\max_{u,v} -b^Tu-h^tv \\ s.t. c=-A^Tu-G^Tv\\ \quad u \ge 0\]总的来说,对于一个general的优化问题来说
\[\min f(x)\\ s.t. \quad h_i(x) \le 0, i=1,2,...,m\\ \quad l_j(x)=0,j=1,2,...,r\] 我们定义Lagrangian为
\[L(x,u,v)=f(x)+\sum^{m}_{i=1} u_{i}h_{i}(x)+\sum_{j=1}^{r}v_{j}l_{j}(x),注意u_{i} \ge 0, v_{j} \in R\]对于任意可行点x,我们都有$L(x,u,v) \le f(x)$。定义Lagrange dual function为$g(u,v)=\min_{x} L(x,u,v)$,我们有
\[f^* \ge L(x,u,v) \ge \min_x L(x,u,v) = g(u,v)\]其对偶形式是下式,所以对偶形式是关于Lagrangian的min-max问题
\[\max_{u,v} g(u,v) \quad s.t. \quad u \ge 0\] 需要注意的是,对偶问题一定是凸的,因为他是关于$u,v$的函数,而不是$x$。现在,我们假设上式的最优值是$g^*$,这里可以保证$f^* \ge g^*$,这个定理称为weak duality,即使原问题不是凸的,也是可以保证的。当然,有了weak duality,一定就有strong duality,即满足$f^* =g^*$,这时候原问题的解,就等价于对偶问题的解啦。为了要得到这个strong duality,需要函数满足一个条件Slater’s Condition,这个条件还算比较仁慈,他说的是:如果原问题是凸的,并且他的dom中至少有一点$x$是严格可行的(即$h_{i} (x)<0,l_{i} (x)=0, 对任意 i成立$),那么这个问题能保证strong duality。
另外,对于LP问题来说,对偶问题的对偶是原问题,而且,如果原问题是可行的,或者对偶问题是可行的话,Strong duality是可以保证的。
要是strong duality不能保证,那么给定原问题的可行点x和对偶问题的可行点u,v,称$f(x)-g(u,v)$是duality gap。又由于$f(x^* )≥g(u,v)$,所以有
\[f(x) - f(x^*) \le f(x) - g(u,v)\] 因此,当duality gap是0的时候,我们就达到了原问题的最优解。当duality gap不等于0的时候,上面这个不等式可以为我们提供一个迭代准则,即当$f(x)-g(u,v)≤ε$,我们能大概得知与最优值的差距。现在来看2个例子,分别是很常用到的SVM问题和Dual Norms问题。
例子1-SVM
支持向量机SVM是一个过分经典的模型了,这里就不赘述。给定SVM的目标函数
\[\min_{\beta,\beta_0,\delta} \frac{1}{2} \|\beta\|_2^2 + C \sum_{i=1}^n \delta_{i} \\ s.t. \quad -\delta_i \le 0,i=1,2,...,n\\ \quad 1-\delta_i-y_i(x_i^T\beta + \beta_0) \le 0, i=1,2,...,n\]现在来求他的对偶,引入dual变量$v_{i} \ge 0,w_{i} \ge 0$,整理一下
\[L(\beta,\beta_0,\delta,v,w) = \frac{1}{2} \|\beta\|^2_2 + C\sum_{i=1}^n\delta_i - \sum_{i=1}^nv_i \delta_i + \sum_{i=1}^{n} w_i (1-\delta_i-y_i(x_i^T\beta+\beta_0)) \\ \quad = \frac{1}{2} \|\beta\|^2_2 - \sum_{i=1}^n w_iy_ix_i\beta - \sum_{i=1}^n w_iy_i\beta_0 + \sum_{i=1}^n (C-v_i-w_i)\delta_i + \sum_{i=1}^n w_i\]现在,为了要求Lagrange dual function $g(w,v)$,我们需要对$β,β_{0},δ$求最小,首先看来$\beta$。
\[\min_{\beta} \frac{1}{2} \|\beta\|^2_2 - \sum_{i=1}^n w_iy_ix_i\beta \\ = \frac{1}{2} \beta^T \beta- W^T \hat{X} \beta \quad where \quad \hat{X}的第i行是y_ix_i\]可以得到上式的解是$\beta=\hat{X}^{T}W$,在最小化下式(这里是关于$\delta_{i}$求导,而不是$\delta$)
\[\min_{\beta_0} -\sum_{i=1}^n w_i y_i \beta_0 \\ \min_{\delta} \sum_{i=1}^n (C-v_i-w_i)\delta_i\]得到$\sum_{i=1}^{n}w_{i}y_{i}=0, C-v_{i}-w_{i}=0$,由于$v_{i} \ge 0$,所以$w_{i} \le C$。现在把所有的东西都带回到$L$函数中,得到
\[g(w,v) = g(w) = -\frac{1}{2}W^T\hat{X}\hat{X}^TW + W^T1\]所以,SVM的对偶形式是这个:
\[\max_{w} -\frac{1}{2}W^T\hat{X}\hat{X}^TW + W^T1 \\ s.t. \quad 0\le w_i \le C, i=1,2,...,n\\ \quad W^Ty=0\] 可以看出这个问题是满足Slater’s Condition的,比如$w_{i}=0$,所以对偶问题的解,就是原问题的解,而且这个形式好解多了,这也是对偶的带来的便利。值得一说的是,在求$g(w,v)$的过程中所得到的那些条件,如$β=\hat{X}^{T} W$,也正是后面要说的KKT条件的一部分,这其实并不是巧合。
例子2-Dual Norm
给定任意Norm记为$|*|_{+}$,那么dual norm定义为:
\[\|x\|_{d}=\max_{\|z\|_{+} \le 1} z^{T}x\]可以看下面的两个例子,更加的直观

至于norm的对偶norm为啥是这个形式,这里就不证(黏)明(贴)了,它需要用到一个叫Holder不等式的东西。不过,关于Dual Norm还是有一些结论可以看下的
- 如果$|x|$是一个norm,$|x|_{d}$是它的对偶norm,那么满足$abs(z^{T}x) \le |z| |x|_{d}$
- $|x|_{dd} = |x|$
- Sub-differential of Norm,其中$\theta$是一个norm,$\theta^{*}$对偶norm。{$z;asdf$}表示满足asdf的所有z
0x02_2 KKT conditions
先上结论,给定下面的优化问题:
\[\min f(x)\\ s.t. \quad h_i(x) \le 0, i=1,2,...,m\\ \quad l_j(x)=0,j=1,2,...,r\]它的KKT条件(Karush-Kuhn-Tucker Conditions)是由四个部分组成的,分别是
\[Stationary:0 \in \partial f(x) + \sum_{i=1}^m u_i\partial h_i(x) + \sum_{j=1}^r v_i\partial l_i(x) \\ Complementary:u_{i}h_{i}(x)=0 \quad \forall i\\ Primal\quad Feasibility:h_i(x) \le 0, l_j(x)=0, \quad \forall i,j \\ Dual\quad Feasibility:u_i \ge 0 \quad \forall i\] 如果说这个优化问题具有强对偶性,那么有,符合KKT条件的点$x,u,v \leftrightarrow x,u,v$是原问题和对偶问题的解。原因在于,强对偶性保证了其duality gap为零,则有
\[f(x^*) = g(u^*,v^*) = \min_{x}f(x) + \sum_{i=1}^m u_i^* h_i(x) + \sum_{j=1}^r v_j^*l_j(x) \\ \le f(x^*) + \sum_{i=1}^m u_i^* h_i(x^*) + \sum_{j=1}^r v_j^*l_j(x^*) \\ \le f(x^*)\] 因为上式中的不等式都应该是等式。所以,第一个不等式告诉我们,$x^*$能最小化$L(x ,u^*,v^*)$,$即0 \in \partial_{x} L(x^{*},u^{*},v^{*})$,也就是stationary condition成立;第二个不等式告诉我们,$u_{i}^{*} h_{i} (x^{*})=0$,也就是complementary condition,最后primal/dual feasibility condition当然也成立,不然解都不是可行的了。反过来,当满足KKT条件的时候,也可以反推出上式成立。另外当原问题是无约束优化的时候,KKT条件就相当于是subgradient optimality condition。
回一下上一节提到的SVM例子,我们在求Dual的时候已经得到Stationary,现在再补充其他条件
\[\min_{\beta,\beta_0,\delta} \frac{1}{2} \|\beta\|_2^2 + C \sum_{i=1}^n \delta_{i} \\ s.t. \quad -\delta_i \le 0,i=1,2,...,n\\ \quad 1-\delta_i-y_i(x_i^T\beta + \beta_0) \le 0, i=1,2,...,n\]Stationary:$\sum_{i=1}^{n}w_{i}y_{i}=0, C-v_{i}-w_{i}=0, \beta=\hat{X}^{T}W=\sum_{i=1}^{n}w_{i}x_{i}y_{i}$
Complementary:$v_{i}\delta_{i}=0, w_{i}(1-\delta_{i}-y_{i}(x_{i}^{T}\beta+\beta_{0}))$
有条件可以看出,$w_{i} \in [0,C]$,那么可以定义满足这样的$w_{i}$对应的点叫做支持向量
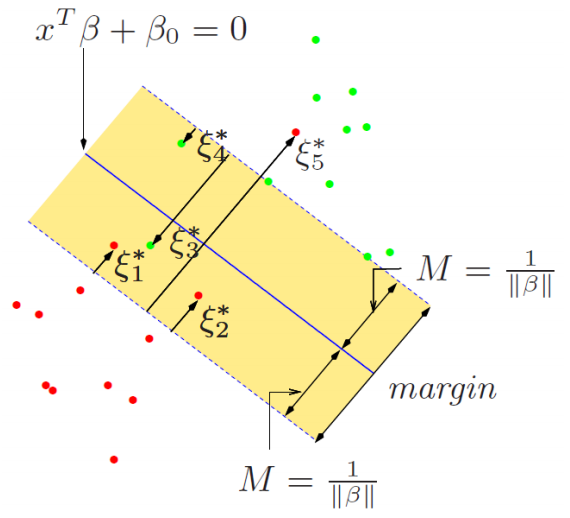
- 如果$0<\delta_{i}<1$,则,$v_{i}=0,w_{i}=C,1-\delta_{i}-y_{i}(x_{i}^{T}\beta+\beta_{0})=0$,也就是说,$y_{i}(x_{i}^{T}\beta+\beta_{0}) < 1$,点i落在间隔边界和超平面之间,分类正确
- 如果$\delta_{i}=0$,则$w_{i} \in [0,C]$
- 若$v_{i} > 0, w_{i} \in (0, C]$,则$1-\delta_{i}-y_{i}(x_{i}^{T}\beta+\beta_{0})=0 \rightarrow y_{i}(x_{i}^{T}\beta+\beta_{0}) = 1$,点在间隔边界上面
- 若$v_{i} = 0, w_{i} =0$,则$1-\delta_{i}-y_{i}(x_{i}^{T}\beta+\beta_{0})=0 \rightarrow y_{i}(x_{i}^{T}\beta+\beta_{0}) > 1$,点不是支持向量
- 如果$\delta_{i}=1$,则$v_{i}=0,w_{i}=C,y_{i}(x_{i}^{T}\beta+\beta_{0}) = 1$,点在超平面上
- 如果$\delta_{i}>1$,则$v_{i}=0,w_{i}=C,y_{i}(x_{i}^{T}\beta+\beta_{0}) <0$,点在误分类。
所以,KKT条件不仅仅用于find solution,也能让我们全面的分析问题的解。值得一提的是,对于软间隔SVM问题来说,原问题和对偶问题都不是严格凸函数,所以这种情况下的SVM的解b是不唯一的,但是w是唯一的,而对于线性可分SVM来说,原问题是严格凸函数,对偶问题是非严格凸函数(这里可以看到,原问题是严格凸函数,并不意味着对偶问题是严格凸函数),解w和b都是唯一的。(喜欢的朋友,可以去看下这篇NIPS的论文,Uniqueness of the SVM Solution)
0x02_3 Duality Uses and Correspondences
从上一节可以看出对偶的作用有两点,一个是借用dual gap来做算法迭代的停止准则,另一个是依赖在强对偶的情况下的KKT的条件。这一节旨在引入另一个概念 共轭函数(Conjugate Function),可以用来辅助对偶形式的构造。那啥是共轭函数呢。给定一个函数$f$,他的共轭函数定义为:
\[f^*(y) = \max_{x} y^Tx - f(x)\]
由于共轭函数是关于$y$的一些凸函数的逐点上确界,所以无论函数$f$是不是凸函数,他的共轭函数一定是凸函数。对于共轭函数而言,可以把它看做是函数$f(x)$与函数$y^{T} x$之间的最大间隔。如果$f$可微,在满足$y=∇f(x)$的点$x$处的差值最大。假设这个点为$x_{0}$,则有$y=\triangledown f(x_{0}), f^*(y) = yx_{0} - f(x_{0})=\triangledown f(x_{0}) x_{0} - f(x_{0}) $,进一步化解为$\triangledown f(x_{0}) =\frac{f(x_{0}) - (-f^*(y))}{x_{0} - 0}$
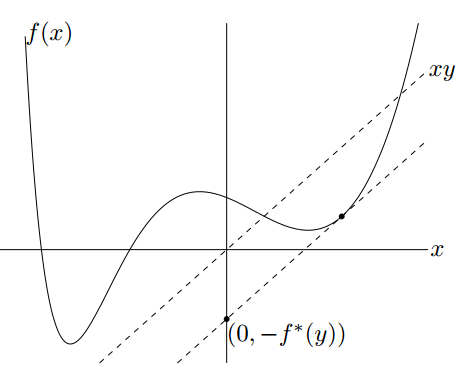
我们已经说了,共轭函数的作用就在于 他能使我们更快的得到对偶问题!那我们先看看共轭函数有没有什么好的性质可以使用
-
对于任意的$x,y$,满足$f(x) + f^{*}(y) \le x^{T}y$
-
对于任意函数$f$,他的共轭函数的共轭函数,值不大于原函数:$f^{**}(x) \le f(x)$
-
如果函数$f$是凸的或者凹的,那上面两个性质都可以取等号
-
指示函数的共轭函数是支持函数(Support Function),即$f(x)=I_{C}(x),f^{*}=\max_{x \in C} y^{T} x$
-
范数的共轭是指示函数
那么conjugate function到底有啥好的呢,如何加快求解dual?下面是一个Lasso Dual的小例子,给定$y \in R^{n}, X \in R^{n,p}$
\[\min_{\beta \in R^p} \frac{1}{2} \|y-X\beta \|_2^2 + \lambda \|\beta\|_1\] 注意到,这里是无约束的问题,无法通过拉格朗日引入对偶问题,事实上这里会用到一个dual trick,引入额外的等式约束
\[\min_{\beta \in R^p} \frac{1}{2} \|y-z \|_2^2 + \lambda \|\beta\|_1 \\ s.t. X\beta = z\] 这样就可以搞拉格朗日咯,那就搞起来
\[\min_{z,\beta} L(z,\beta,u) = \frac{1}{2} \|y-z\|_2^2 + \lambda \|\beta\|_1 + u^T(z-X\beta)\\ = \min_{z} \{ \frac{1}{2} \|y-z\|_2^2 + u^Tz \} + \min_{\beta} \{ \lambda \|\beta\|_1 - u^TX\beta \}\] 第一项的min可以直接求导,完美,那就求呗,反正最后是$y-u=z$,带入得下式,(另外可以看出lasso的解一定会满足y-u=z=Xβ,而这个等式也是KKT条件之一)
\[\frac{1}{2} \| y\|_2^2 - \frac{1}{2} \|y-u\|_2^2\] 第二项,有lasso,完了,要求subgradient吗?当然大可不必,我们把这个式子捣鼓一下,就成了conjugate function咯
\[\min_{\beta} \{ \lambda \|\beta\|_1 - u^TX\beta \} = -\lambda \max_{\beta} \frac{u^TX\beta}{\lambda} - \|\beta\|_1\\ = -\lambda \max_{\beta} \frac{(X^Tu)^T}{\lambda}\beta - \|\beta\|_1\] 这是L1的conjugate function,当然等于一个指示函数,最后得
\[\frac{1}{2} \| y\|_2^2 - \frac{1}{2} \|y-u\|_2^2 - I_{\|X^Tu\|_{\infty} \le \lambda}\] 所以Lasso的对偶就是下式
\[\max_u \frac{1}{2} \|y\|_2^2 -\frac{1}{2}\|y-u\|^2_2\\ s.t. \|X^Tu\|_{\infty} = (X^T)^{-1} \|u\|_{\infty} \le \lambda\] 上式中的约束条件可以看成是一个polyhedron $C$,则Lasso对偶问题转化为最小化点y到polyhedron $C$的最短距离,如下所示,其中$C$就是那个约束条件
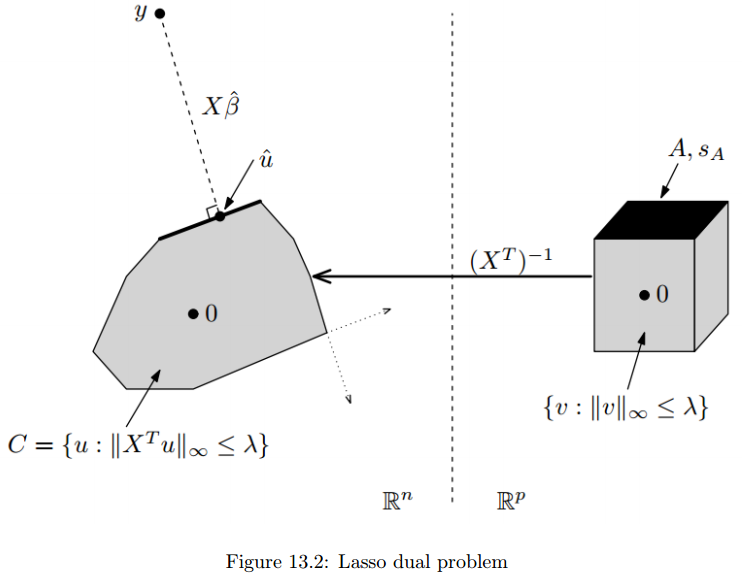
事实上,对于更一般的问题,共轭函数也有很好的特性
\[\min_x f(x) + g(x) \leftrightarrow \min_{z,x} f(x) + g(z) \quad s.t. \quad z=x\] 其对偶就可以直接写成下式
\[\min_{z,x} L(x,z,u) = \min_{z,x} f(x) + g(z) + u^T(z-x) = -f^*(u) - g^*(-u) \\ \rightarrow \max_{u} -f^*(u) - g^*(-u)\]0x03 Second-order Method
0x03_1 Newton Method
前面说,gradient methods的解释是,对原函数进行泰勒展开,然后做二次近似之后的最小值为下一次的迭代值。同样Newton method也是同样的方法,只不过是使用了不同的二次近似的方法所得。考虑这个无约束凸优化问题$\min_{x} f(x)$,对于gradient method,有下式,然后关于y求最值,即得下次的更新
\[f(y) \approx f(x) + \triangledown f(x)^T (y-x) + \frac{1}{2t} \|y-x\|^2_2\]对于牛顿法来说,二阶方法就体现出来了
\[f(y) \approx f(x) + \triangledown f(x)^T (y-x) + \frac{1}{2} (y-x)^T \triangledown^2f(x)(y-x)\]对于凸优化任务来说,$\triangledown ^{2}f(x)$是半正定的,对称的,所以,我们对上式中$y$求导:
\[\triangledown f(x) + \frac{1}{2} \left( \triangledown^2 f(x) + \triangledown ^2f(x)^T \right) (y-x) = \triangledown f(x) + \triangledown ^2 f(x) (y-x) = 0\]可以解得newton的更新公式:
\[y=x-(\triangledown ^2 f(x)) ^{-1} \triangledown f(x)\]这种方式比gradient的近似方式使用了更多的Hessian矩阵的信息,所得结果是沿着导数的负Hessian方法进行。下图可以看出,newton法并没有像gradient method一样沿着等高线的垂直方向进行,反而是直逼最值方向。
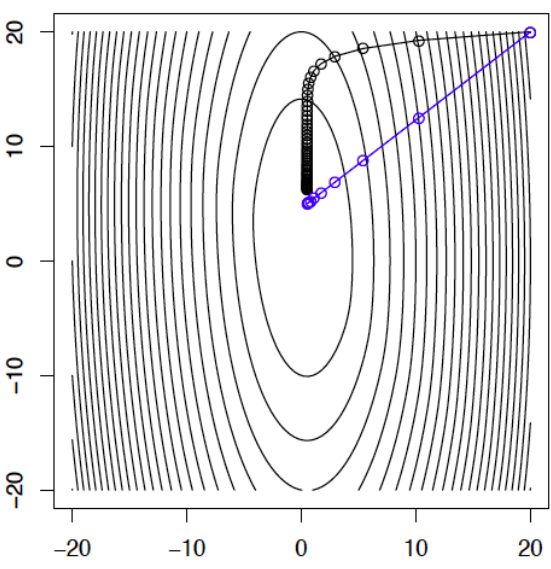
出现这个想象的一种解释是,假设当前迭代点为$x$,下一次的方向是$v$,当然,如果下一步就能到最小值就完美了,那么假设下一步就是最小值,那么有$∇f(x+v)=0$,现在用泰勒进行展开,得
\[\triangledown f(x+v) \approx \triangledown f(x) + \triangledown ^2f(x) v = 0 \\ \rightarrow v = - (\triangledown ^2 f(x))^{-1} \triangledown f(x)\]这恰恰就是newton法的更新公式,而且,这个$v$与newton decrement有一定联系,具体来说是,newton decrement是$v$关于$\triangledown^{2} f(x)$的Hessian范数。什么是Hessian范数呢?它定义为$|v|_{A}=\sqrt{v^{T}Av}$。因此,newton decrement表示为:
\[\lambda(x) = \|v\|_{\triangledown ^2 f(x)}= \sqrt{ \triangledown f(x)^T (\triangledown^2 f(x))^{-1} \triangledown f(x)}\]newton decrement的含义是指代了$f(x)$与它的二阶近似的差距:
\[f(x) - \left( f(x) + \triangledown f(x)^T (y-x) + \frac{1}{2} (y-x)^T \triangledown^2f(x)(y-x) \right)\\ =f(x) - \left( f(x) - \frac{1}{2} \triangledown f(x)^T (\triangledown^2 f(x))^{-1} \triangledown f(x) \right) \quad (带入y=x-(\triangledown ^2 f(x)) ^{-1} \triangledown f(x))\\ =\frac{1}{2} \triangledown f(x)^T (\triangledown^2 f(x))^{-1} \triangledown f(x) = \frac{1}{2} \lambda^2(x)\] 注意,虽然pure newton法的是没有步长这个概念的,或者说认为步长为1。但是仍然可以使用Backtracking的方法来选择更适合的步长:当$f(x+tv)>f(x)+at∇f(x)^{T} v$ 时,收缩步长$t=βt$,否则进行牛顿更新,这里的$a,β$的取值和gradient descent一样,而$v=-(∇^{2} f(x))^{-1} ∇f(x)$
接下来要说的是,关于牛顿法的收敛性。由于数学不好,还是直接看结论。在列的假设条件成立的情况下:
-
$f$是强凸(对应系数为$m$),二阶可微,$dom(f)=R^{n}$
-
$∇f(x)$是Lipschitz连续,Lipschitz常数为$L$
-
$∇^{2} f(x)$是Lipschitz连续,Lipschitz常数为$H$
其中条件1,2保证了gradient descent的线性收敛,在条件3的加入下,可以保证下面的收敛结论对backtracking 牛顿法成立,并且依赖于两个参数$η,γ$, 其中backtracking的对应系数为$a,β$。假设$k_{0}$表示满足下式的最小值
\[\| \triangledown f(x^{k_0+1})\|_2 < \eta \\ where \quad \eta=\frac{\min \{ 1, 3(1-2a) \} m^2}{H}\]这里的$k_{0}$,把牛顿法的收敛划分成了两个不同阶段,分别是Damped Newton Phase和Pure Newton Phase。具体来说,牛顿法的收敛界为
\[f(x^k) - f^* \le \left\{\begin{matrix} f(x^0) - f^* -\gamma k \quad if \quad k \le k_0 \\ \frac{2m^3}{M^2} (\frac{1}{2})^{2^k-k_0+1} \quad otherwise \end{matrix}\right. \\ where \quad \gamma = \frac{\alpha \beta^2 \eta ^2 m}{L^2}\]当$k<k_{0}$时,称为Damped Newton Phase,这个阶段里算法的收敛并不快,并且如果函数是poorly condition的,甚至难以保证下降性;另一方便,称为Pure Newton Phase,在这个阶段算法收敛很快,具有二次收敛性,一旦进入这个阶段之后,便不会在回到damped newton phase中,backtracking的步长也不在变化。所以,牛顿法的二次收敛速度必须在一定步数之后才能到达。如果想要一开始就达到Pure newton phase,就对初始值的选取有很大讲究。虽然在pure phase牛顿法收敛很快,但是这个方法始终需要计算Hessian矩阵,这个开销是不容小视的额
另外,牛顿法也可以适用于等式约束优化问题,给定下式
\[\min_x f(x) \\ s.t. Ax=b\]等式约束的牛顿法从满足$Ax=b$的点$x^{0}$出发,然后做有限制的Newton更新,使得更新后的值仍然满足$Ax=b$,更新步骤如下
\[x^+ = x + tv\\ where \quad v=\arg\min_{Az=0} \triangledown f(x)^T (z-x) + \frac{1}{2} (z-x)^T\triangledown^2f(x)(z-x)\]这样的更新结果可以保证找出来的方向$v$在满足牛顿方向的同时,满足$Av=0$,使得$Ax^{+}=b$成立。而方向$v$的求解可以直接使用KKT条件。
\[L(w,v) = \triangledown f(x)^T (v-x) + \frac{1}{2}(v-x)^T\triangledown^2 f(x) (v-x) + wAv\\ Primal\_feasibility:Av=0\\ Stationary:\triangledown f(x) + wA + \triangledown ^2f(x)(v-x) = 0\]又因为求$v$的式子中是关于$z$求最小,与$x$无关,所以可以把不含$z$的式子排除在外,从而得到最终的线性组,求出$v$就是等式约束的牛顿更新的方向最优解。所以对于等式约束的一般光滑凸问题,用牛顿法可以把它转化为去求解一个等式约束的二次问题。
\[\begin{bmatrix} \triangledown^2f(x) & A^T\\ A & 0 \end{bmatrix}\begin{bmatrix} v \\ w \end{bmatrix} = \begin{bmatrix} \triangledown f(x) \\ 0 \end{bmatrix}\]前面已说到,牛顿法在计算Hessian矩阵的逆将会变得很麻烦。所以为了解决这个问题,最后要说的是几个牛顿法的变种,包括Modified Newton Methods和Quasi-Newton methods(比如Davidon-Fletcher-Powell (DFP)和Broyden-Fletcher-Goldfarb-Shanno (BFGS)方法),旨在近似的计算一个与$∇^{2} f(x_{k})^{-1}$相似的正定矩阵$S_{k}$,使得$x^{k+1}=x^{k}-a_{k} S_{k} ∇f(x_{k})$ ,其中$S_{k} \in R^{n,n},a_{k} \in R$,如果$S_{k}=I$,就是gradient descent,$S_{k}=∇^{2} f(x_{k} )^{-1}$,就是pure newton method。
保证$S_{k}$是正定矩阵的原因在于保证迭代的过程中的下降性。在第$k$次迭代中,与$∇f(x_{k} )$成钝角的方向是函数值下降的方向,当$S_{k}$是正定矩阵时有下式成立,能保证下降性
\[\triangledown f(x_{k})^T(x_{k+1} - x_k) = -\triangledown f(x_k) \alpha_k S_k \triangledown f(x_k) < 0\]对于modified newton method的一个简单方式是用第一次的迭代的hessian矩阵进行近似,即$S_{k}=∇^{2} f(x_{0} )^{-1}$,如果每次迭代,hessian矩阵的变化不大,这不失为一个很好的近似方法。而对于Quasi-Newton methods,旨在通过使用前k次迭代中的gradient信息来进行hessian矩阵近似。具体来说分为两类:Rank one correction和Rank two correction。在开讲之前,先给出一些记号和算法的中心式子,令$g_{k+1}=∇f(x_{k+1} )$,$g_{k}=∇f(x_{k} ), Q(x_{k} )=∇^{2} f(x_{k} )$,$q_{k}=g_{k+1}-g_{k}=∇f(x_{k+1} )- ∇f(x_{k} ) $,$p_{k}=x_{k+1}-x_{k},H(x_{k} )= Q(x_{k} )^{-1}$,则有
\[Q(x_{k+1}) \approx \frac{q_k}{p_k} \rightarrow q_k = Q(x_{k+1}) p_k \rightarrow H(x_{k+1})q_k \approx p_k\]Rank one correction: 为了加快计算$H(x_{k+1})$ 的速度,该方法假设了更新式子满足下式,由一个对称的秩1矩阵构成,其中$a_{k},z_{k}$是未知量,$a_{k}$是常数
\[H(x_{k+1}) = H(x_k) + \alpha_kz_kz_k^T\]我们把这个更新式子带入回去,可以得到下式(贴图了,makedown打公式太麻烦了)
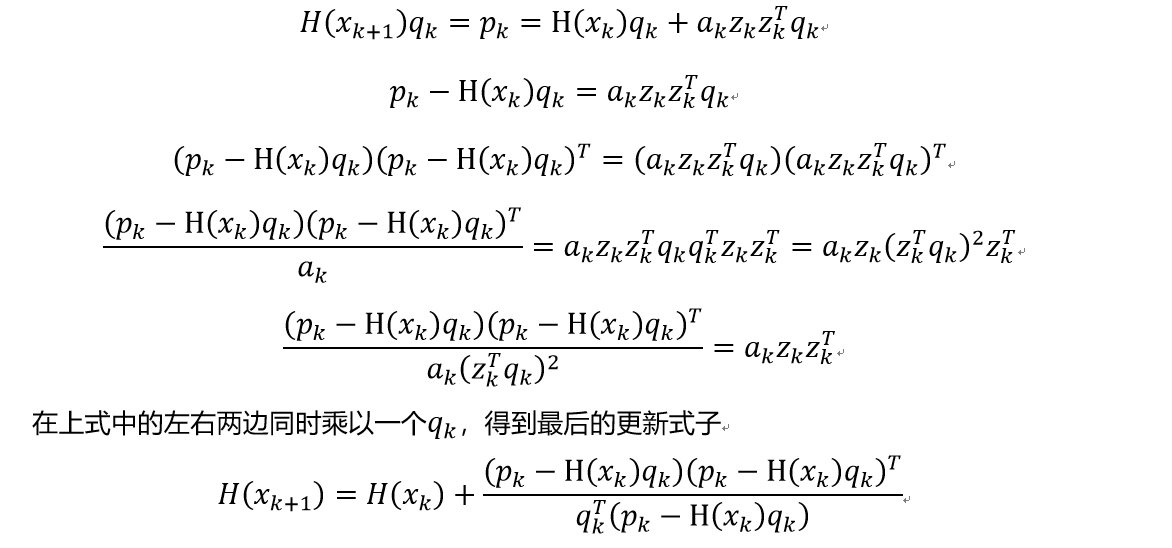
Rank Two Correction:顾名思义,该方法是由两个对称的秩1矩阵来进行迭代近似,假设更新式子为下式,其中$a_{k},u_{k},β_{k},v_{k}$是未知量,$a_{k},β_{k}$是常数
\[H(x_{k+1}) = H(x_k) + \alpha_ku_ku_k^T + \beta_k v_k v_k^T\]同理我们同样带入到上式,得到
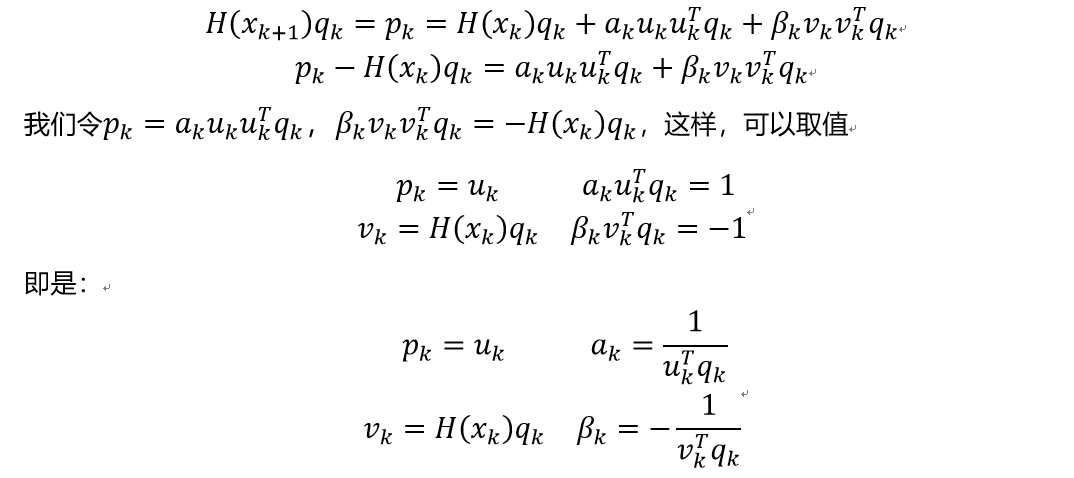
这样我们就得到了DFP算法的更新公式
\[H(x_{k+1}) = H(x_k) + \alpha_ku_ku_k^T + \beta_k v_k v_k^T = H(x_k) + \frac{p_kp_k^T}{p_k^Tq_k} - \frac{H(x_k)q_k q_k^T H(x_k)}{(H(x_k)q_k)^Tq_k}\]而对于更为有名的BFGS算法,他的更新对象却不再是$H(x_{k+1} )$,而是$Q(x_{k+1} )$,此时他的更新式子变成下式
\[Q(x_{k+1}) = Q(x_k) + \frac{q_kq_k^T}{q_k^Tp_k} - \frac{Q(x_k)p_k p_k^T Q(x_k)}{(Q(x_k)p_k)^Tp_k}\]当然,我们还需要根据$Q(x_{k+1} )$,来求出他的逆$H(x_{k+1} )$,此时需要用到两次的Sherman-Morrison公式,最后得到BFGS算法的更新结果如下
\[H(x_{k+1}) = H(x_k) + \left ( 1+\frac{q_k^T H(x_k)q_k}{p_k^Tq_k} \right) \frac{p_kp_k^T}{p_k^Tq_k} - \frac{p_kq_k^TH(x_k) + H(x_k) q_k p_k^T}{q_k^Tp_k}\]虽然BFGS算法过程不如DFP算法的过程直接,但是数值计算表明,BFGS算法具有更好的近似效果。另外,对于BFGS算法来说,他为了进一步解决内存问题(即$H(x_{k} )$可能会很大,内存容不下),还有L-BFGS算法,该算法是只记录初始的$H(x_{0} )$,在第$k$次迭代的时候,通过迭代公式计算出$H(x_{k} )$,已达到增加cpu计算,降低内存的目的。
0x03_2 Barrier Method
前文说到,对于等式约束的一般光滑凸问题,用牛顿法可以把它转化为去求解一个等式约束的QP问题;而这个等式约束的二次问题可以在KKT的帮助下得到closed-form;对于具有不等式约束的一般光滑凸问题,就是本节的内容,barrier method,把他转化为等式约束问题,当然了,barrier method也同样可以适用于等式约束问题。给定下面的优化问题,其中$f$和$h$都是凸函数并且二次可微,定义域为$R^{n}$
\[\min f(x)\\ s.t. \quad h_i(x) \le 0, i=1,2,...,m\]我们可以采用对待指示函数的方法,来处理不等式约束,定义一个barrier区域,问题等价于下式这种无约束优化问题,使得原始不等式仍然成立
\[\min f(x) + \sum_{i=1}^m I_{h_i(x) \le 0} (x)\]但是指示函数还是比较难求解的,我们可以定义一个log barrier 区域,表示为$\phi(x)=-\sum_{i=1}^{m} log(-h_{i}(x)) $用来近似指示函数。原问题近似于下式,当$h$趋于0的时候,log barrier趋于无穷大。所以要求额外增加一个参数$t$,为一个比较大的数,保证在$h_{i}(x) \le 0$时,log barrier趋向于0,满足原指示函数的要求(不同$t$下的近似,如下图)。所以,对于
\[\min f(x) - \frac{1}{t} \sum_{i=1}^{m} log(-h_{i}(x))\]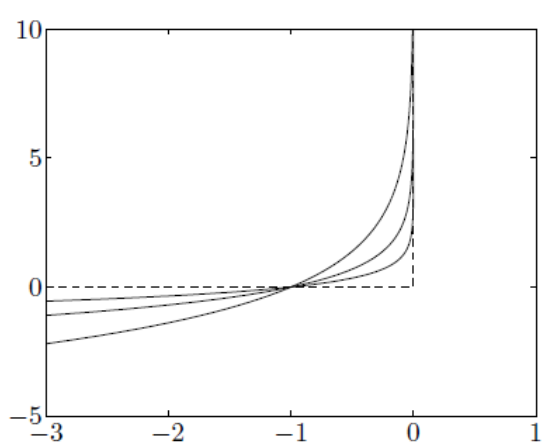
所以,对于既有不等式约束和等式约束的情况,我们可以把原问题写成下式进行求解
\[\min tf(x) + \phi(x)\\ s.t. Ax=b\]这个优化问题可以通过带有等式约束的牛顿法求解出来,具体步骤见前一节,他的最优值$x^{*}$是关于$t$的一个函数,记为central path $x^{*} (t)$。可以看出Barrier method的迭代点是在可行点集内部沿着central path进行移动的,期望当$t \rightarrow \infty$时,$x^{*} (t)$趋近于原始的最优解。同时,对接近可行点集边界上的点施加越来越大的惩罚,对可行点集边界上的点施加无限大的惩罚(比如当h趋于0的时候,log barrier趋于无穷),这好比边界是一道高压电网,阻碍迭代点穿越边界。因此,barrier method也称为内点法(interior point method)。那么怎么找这个central path呢?
一般来说,central path 上的points $x(t)$需要满足以下两个条件:
- 严格可行。$Ax=b, h_{i}(x) < 0$
- 存在对偶变量$v$使得下式拉格朗日的导数等于0成立
对于原问题来说,他的stationary condition是下式
\[\triangledown f(x) + \sum_{i=1}^m \hat{u}_i \triangledown h_{i}(x) + A^T \hat{v} = 0\]所以,在central points对应的对偶可行点,可以构造为下式。这里特意把$x,u,v$都明确写成了与t有关的函数。
\[u_{i}(t) = - \frac{1}{t h_{i}(x(t))} \\ v(t) = \frac{\hat{v}}{t}\]这种构造方式可以强制与KTT建立联系,使得对应的duality gap等于$\frac{m}{t}$。
\(g(u(t), v(t)) = f(x(t)) + \sum_{i=1}^m u(t) h_i(x(t)) + v(t)^T (Ax(t) - b) = f(x(t)) - \frac{m}{t}\) 所以当$t \rightarrow \infty $时,$x(t)$才会趋近于原始的最优解,此时我们写下“近似的”KKT条件为下式,可以唯一不同的地方在于complementary condition,看到当$t \rightarrow \infty $时,complementary才近似为零,此时等价于真实的KKT条件。
\[Stationary:\triangledown f(x(t)) + \sum_{i=1}^m u_i(t) \triangledown h_{i}(x(t)) + A^T v(t) = 0 \\ Perturbed \quad complementary:u_i(x)h_i(x(t)) = -\frac{1}{t} \\ Primal \quad feasibility:h_i(x(t)) \le 0, Ax(t) = b\\ Dual \quad feasibility:u_i(t) \ge 0\]那么barrier method是不是直接选择一个很大的$t$,然后求解等式优化问题呢?答案是否定的,因为这样满足条件的$t$往往很大很大,这样会造成计算上不稳定,实际中往往采用沿着central path,一步一步增加t的大小。他的算法过程如下图所示,给定初始值$t^{0}>0$,barrier parameter $μ>1$,使用Newton method求解出最优值$x^{0}=x(t)$,再增长$t$,进行第二次迭代,直到duality gap $m/t≤ε$。

虽然Barrier Method可以处理带有不等式约束的凸优化问题,但是Primal-dual interior point methods经常更加有效,尤其是在高精度要求的场所。与单纯的barrier method比起来,这个算法并不需要迭代点是可行点。具体细节就不写了(没看懂,算了算了)
0x03_3 Proximal Newton Method
考虑前面一阶方法中说到的proximal gradient descent,这种方法,假设目标函数$f(x)$可以分解为光滑凸函数$g(x)$和可能光滑的凸函数$h(x)$两部分,然后迭代的对$g$的二阶泰勒展开求最小,以达到加速收敛的目的。那牛顿法当然也是可以加速的。proximal gradient descent和其他的一阶的方法一样,二阶泰勒展开是将Hessian替换为了$\frac{1}{t} I$,而这正是与二阶的牛顿法的区别。所以如果不用$\frac{1}{t} I$进行近似,就得到了Proximal Newton Method。
首先,定义scaled proximal mapping为下式,其中给定正定矩阵$H$,$| x|_{H}^{2}=x^{T}Hx$,当$H=\frac{1}{t}I$,那就是proximal gradient descent中的proximal operator。
\[Proximal\_operator:Prox_{h}(x) = \arg \min_z \frac{1}{2t} \|z-x \|_2^2 + h(z)\\ Proximal\_gradient\_descent: Prox_{h,t}(x-t \triangledown g(x)) =\arg \min_z \frac{1}{2t} \|z-(x - t \triangledown g(x)) \|_2^2 + h(z)\\ Scaled\_proximal\_mapping:Prox_{h}(x) =\arg \min_z \frac{1}{2t} \|z-x \|_H^2 + h(z)\\ Proximal\_newton:Prox_{h}(x-H^{-1}\triangledown g(x)) =\arg \min_z \frac{1}{2t} \|z-(x-H^{-1}\triangledown g(x)) \|_H^2 + h(z)\\ = \arg \min_z \triangledown g(x_{k-1})^T (z-x_{k-1}) + \frac{1}{2} \left( z-x_{k-1} \right)^T H \left( z-x_{k-1} \right) + h(z)\]套入后,得到的更新式子就和3.1节里牛顿法推导很像了,只是多了一个$h(z)$,所以当$h(z)=0$的时候,这就是牛顿法。总的说来,proximal gradient descent允许我们把最小化$g(x)+h(x)$,变成最小化一系列子问题:$‖b-x‖_{2}^{2}+h(x)$,这个子问题的求解复杂度取决于$h(x)$,而proximal newton是把问题变成最小化一系列子问题:$b^{T} x+x^{T} Ax+h(x)$,求解的复杂度取决于$A$与$h(x)$,一般来说,这些子问题是求解复杂度是很高的,所以在子问题能比较方便求解的时候,proximal newton是很高效的算法,虽然子问题不容易求解,并且求解这些子问题,往往没有direct solution,必须迭代求解,所以子问题的解通常不是个精确的解,但是整个算法却能保证所需的收敛的迭代次数是比较少的。
另外,proximal newton的两个例子就是glmnet和QUIC算法。其中glmnet是用来求解L1-regularized generalized linear model,QUIC是用来求解graphical lasso问题。同时,对于hessian矩阵的计算问题,同样有基于Proximal quasi-Newton methods的方法。如果$h(x)=I$,那么proximal newton就是projected newton。