认识了一个大佬,连续几年坚持在CSDN上更新技术文章,很是佩服。
因此,我也想把博客再维护起来,多总结总结,多思考思考
0. 说在前面的话
最近在学习一个小项目的时候,接触到了课程学习(Curriculum Learning),简单做了个Survey之后才发现,以前了解的自步学习(Self-paced Learning)也属于课程学习的范畴。因此,借此机会也整理一下课程学习的相关内容,便于以后深入学习。
由于深度模型能很好地支持模型结构的可视化,极大降低了学习门槛,再加上业界数据和计算性能的加成,Deep Learning无论是在学术界还是工业界,已经是飞速发展。只要给定数据和计算资料,我们便可以一股脑的把数据喂给模型,经过调参之后,模型输出我们预定的目标。这其中值得探索的问题是,人类或者动物在学习一个知识或者一个任务的时候,并不是毫无章法的。我们总是先从简单的知识开始,并逐渐去学习更加复杂的知识或概念,就像先上小学、中学后,再读大学一样,直接让一个小学生学习微积分怕是难上加难。这就是课程学习想要解决的问题,在训练模型的时候,训练样本的顺序会影响最终的学习效果,甚至模型收敛效率。课程学习的概念是2009年由Bangio提出,他认为模型训练的时候,应该先训练简单的数据,然后不断的提升数据复杂度。
1. 课程与课程学习
1.1 课程 Curricula
上文简单描述了课程学习的初衷,那么课程是指什么呢?课程可以定义为下面的表述方式
令$T$表示任务的集合,$D^{T}$表示所有任务中的数据的集合,一个课程curricula定义为一个有限无环图,$C=(V,\eta,g,T)$,这里$V$表示图里的点集,$\eta$表示有向边的集合,$g$表示一个从$D^{T}$中的取数函数,在这个有向无环图中,如果节点$v_{j}$和节点$v_{k}$满足$v_{j} \rightarrow v_{k}$,则节点$v_{j}$所表示的任务应该要优先执行。倘若在强化学习的环境下,可以将第$i$个任务表示为$m_{i}=(S_{i}, A_{i}, p_{i}, r_{i}), m_{i} \in T$,其中,$S_{i}$表示第$i$个任务的状态集合,$A_{i}$表示第$i$个任务的动作集合,$p_{i}$是环境的转移矩阵,$r_{i}$是Reward function
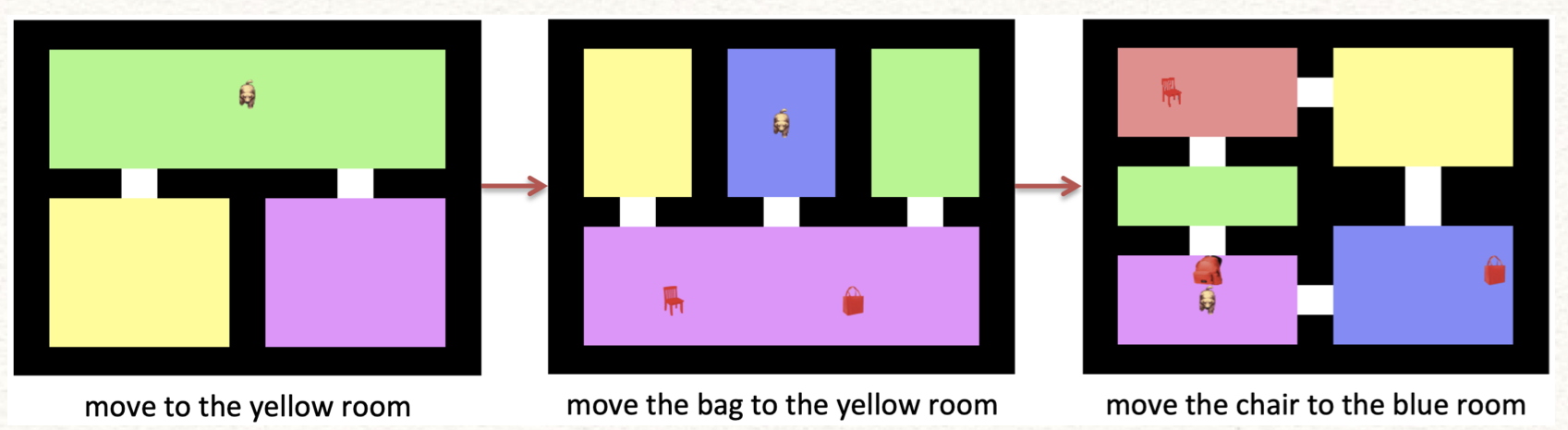
总的来说,课程可以看成是若干个task组成的有向无环图(如果只有一个task,那么课程是一个有序的Experience,下文如无明确说明,都指代是Task)。这里的有向无环图允许Task之间是一对一的序列,也可以是多对一的关系。因此,我们希望能巧妙的为某个目标学习任务制定专门的前驱任务,以供模型良好的学习。以下图为例,如果我们的目标任务是希望Agent在第三个地图上把椅子移动到蓝色的房间,那么,我们或许可以先制定前两个相对简单的地图,以供模型学习。这种制定或者生成课程的过程就称作课程学习。
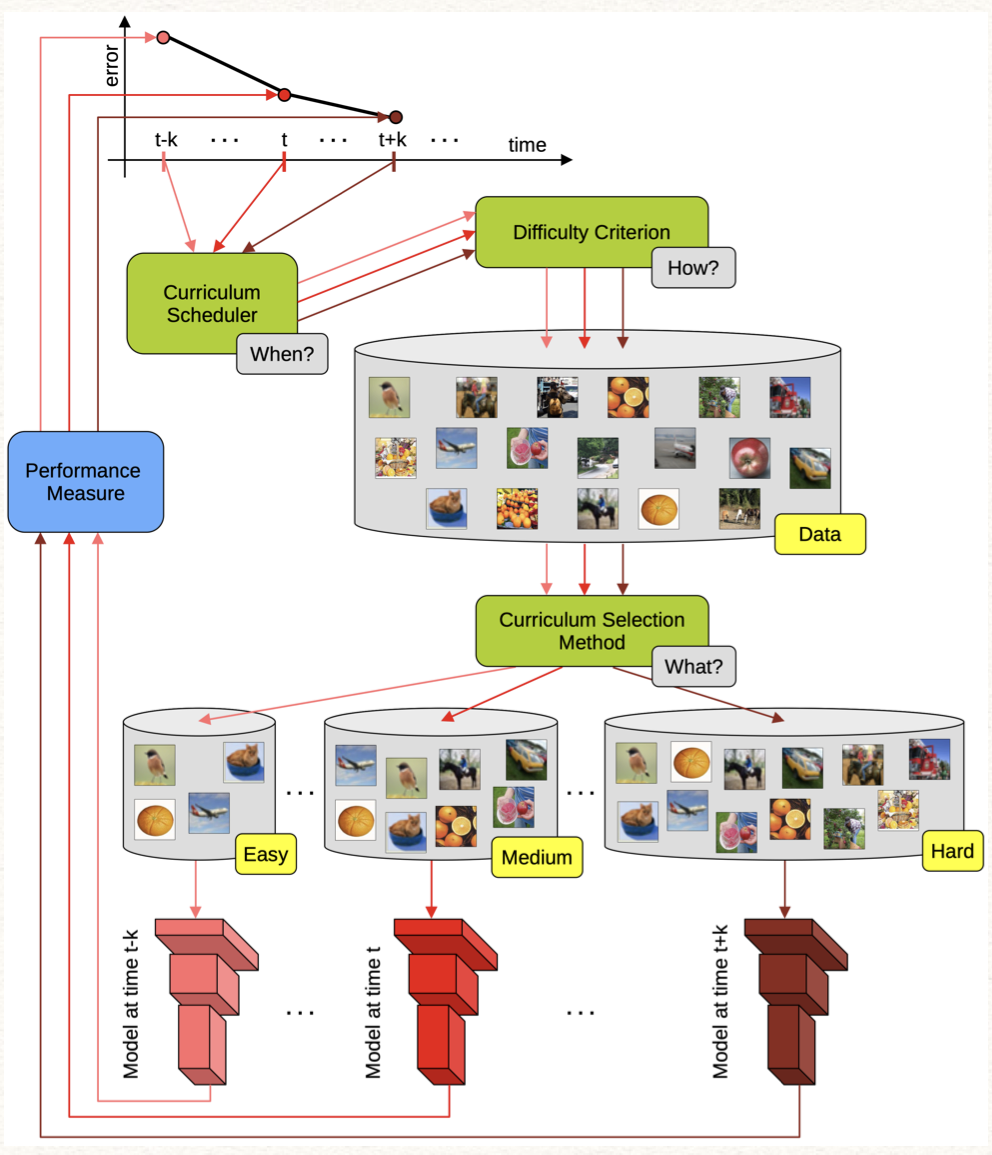
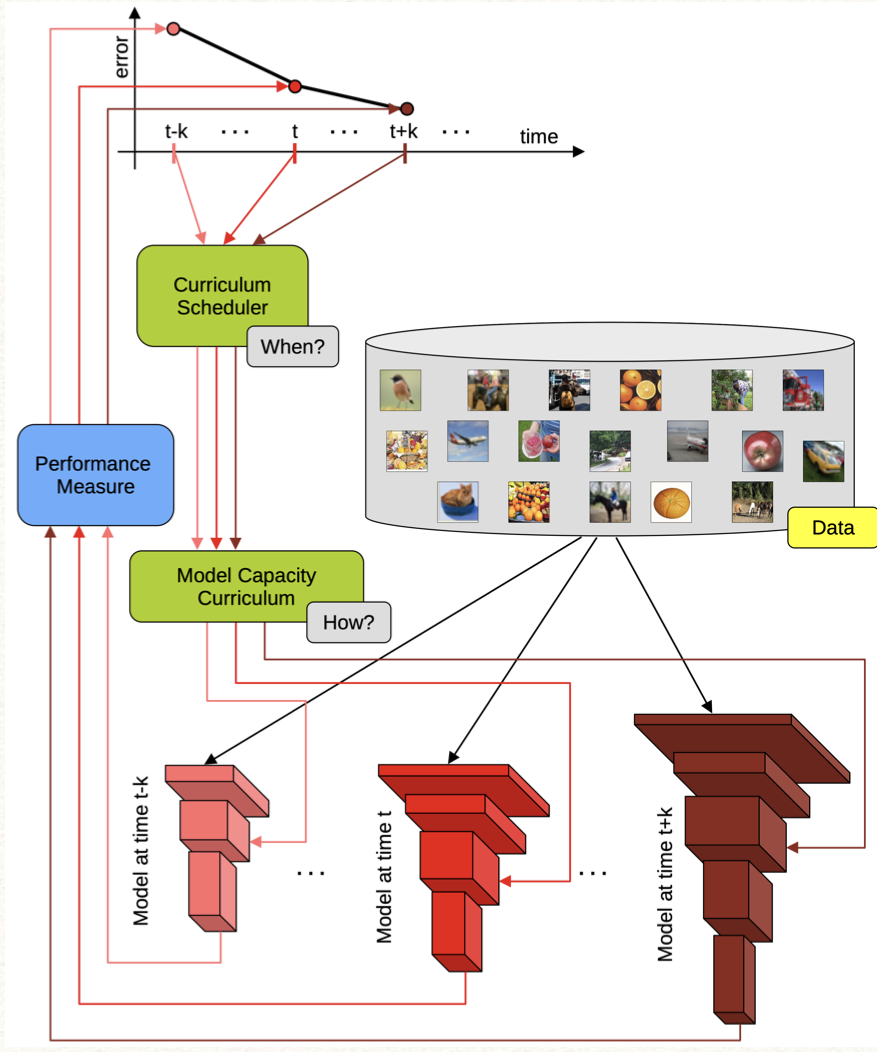
1.2 课程学习 CL
课程学习是生成课程序列的过程,通常来说,为了适应从易到难的训练方式,它有两类学习范式,包括Task-level CL和Model-level CL,下面是他们的区别。
- Task-level的方式,在每次模型训练中的重点在于改变训练数据或者改变本次训练的Task,从数据或Task的角度实现由易到难,引导模型学习;
- Model-level的方式,需要改变模型的复杂程度。它可以看做是一种非凸优化算法continuation method,从一个简单光滑的Objective function开始优化,然后这个function慢慢的转化成一个不那么光滑,不那么好优化的Objective function,直到完成转化成我们最终想要的目标function。
| Task-level:模型不变,改变数据/Task的顺序 | Model-level:数据不变,改变模型复杂度 |
|---|---|
 |
 |
PS:在文献中,通常是Task-Level的算法巨大多数。
在真正去使用课程学习的时候,还有3个关键问题没有给出。
- Task是从哪里来?
- Task之间的顺序如何定义?
- 如何保证模型能在不同Task上越学越好?
这三个问题对应了课程学习的三个组合部分:课程生成(Curriculum Generation)、课程排序(Curriculum Shedule/Sequencing),以及课程知识迁移(Curriculum Knowledge Transfer)。三者的简述信息如下,后面我们从具体算法层面进行深入介绍
- 课程生成:
- 如果仅仅涉及一个task,那么课程便是训练数据本身,此时不涉及课程生成
- 如果task本身很难,那需要生成一些前驱任务(或叫代理任务 Auxiliary Task),比如1.1小节里的前两幅地图。课程生成的方式一般来说是人工制定,或者人工预先给定很多的Task可供选择,或者人工仅仅制定一些Task生成的基本规则,让Task自动生成,实现半自动化课程生成。目前还做不到真正全自动生成task,这东西太难了。
- 课程排序
- 传统的课程学习,课程的顺序是在模型开始训练之前就预先给定了,这种方式没发做到根据模型的学习效果,实时更新反馈新的排序
- 随着技术的不断发展,Automatic Sequencing的算法越来越多。这种方式允许模型在训练的同时,根据模型学习效果,实时更新Sequencing。就像上课一样,老师根据学生的学习效果调整教学形式。
- 课程知识迁移
-
为了保证模型能在不同由易到难的Task上越学越好,需要模型能将前驱Task上学习到的“知识”灵活的应用到后续的任务上。要达到这个效果,需要在不同task上实现知识迁移。比如,
- low-level knowledge transfer:用本轮训练完备后生成的组件(比如,policy,value function V / Q,task model / Agent),初始化下一个task或者 target task的参数
- high-level knowledge transfer:不是直接通过初始化参数的方式来做知识传递,而是用部分组件的信息来引导target task的学习,比如partial policies或者shaping reward
- no transfer:如果只有一个task,即target task,也就不涉及task knowledge transfer了,做好样本顺序管理就好了
-
1.3 评估方法
目前大部分的文献对CL的评估方法集中在验证模型的事后效果,即经过CL训练之后,模型的效果和收敛性。但CL的训练本身可能会很花时间,如何加快CL的训练效率也是个需要关注的问题。
| 评估指标 | 介绍说明 |
|---|---|
| Time to threhold | 相比于Agent重零开始学习(learning from scratch),Agent在经过CL训练之后,在target task上的效果好过一定阈值,所需要的时间、episode或者出招次数,训练次数 |
| Asymptotic Performance | 在target task上收敛之后,Agent的performance较从零开始学习的Agent好多少 |
| Total Reward | 在强化学习的设定下,观察在target task上收敛之后,Agent的累计Reward较从零开始学习的Agent高多少 |
| JumpStart | 考虑在target task的任务初始状态上,CL的方法比不用它的方法,performance好多少 |
1.4 相似领域
CL关注模型的学习是从易到难,在样本或Task层面上来说,CL优先关注简单的数据或者Task,它与以下几个领域稍有不同。
-
Hard Example Mining:HEM的重点在于难区分的样本上,希望能提升模型在这些样本上的效果。
-
Anti-Curriculum Learning:反课程学习比较有意思,它想从难到易的训练模型。这种假设在一些特殊场景下是可能合理的,比如在有noise的场景下的语音识别。
-
Active Learning:主动学习的重点是关注样本的不确定性,希望从无标签数据中,优先选择出具有代表性的样本,并赋予他们真实标签,以让模型在少量的标签样本上,具有较好的模型效果。这里的不确定性包括:样本密度(密度越低,不确定越高)、分类误差(模型无法识别的样本,具有更好的不确定性)、其他信息(比如优先选择能较大影响模型参数所对应梯度信息的数据等等)。主动学习也是一个很有意思的方向,也有不少的工作将主动学习和课程学习相结合。
【AAAI 2019】Query the right thing at the right time: 这篇文章结合了课程学习(具体来说是自步学习)和主动学习。让模型训练的时候,同时考虑样本的不确定性和样本学习的难易程度。他的优化目标为下式
\[min_{f,w,v} \sum_{i=1}^{n_l} (y_i - f(x_i))^2+ \sum_{j=1}^{n_u} [v_j w_j (\hat{y_j} - f(x_j)^2\\ + \lambda(\frac{1}{2}v_j^2-v_j)]+\mu(w^TKw+kw) + \gamma|f|^2 \\ s.t. w_j \in [0,1], v_j \in [0,1], \forall j=1,...,n_u \\ where, \hat{y_j} = -sign(f(x_j))\]其中,$v$是自步学习中的数据权重,衡量了数据学习成本的难易程度,$w$是主动学习中的数据权重。该算法定义self-paced regularizer为$\frac{1}{2}|v|^{2}-\sum_{j=1}^{n_{u}}v_{j}$,这个regularizer的第一项是权重的正则项,保证数据权重尽可能平滑,第二项是self-paced的主要控制部分(配合$\lambda$参数),当无标签数据项的误差大于$\lambda$的时候,$v$的最优解是0,反之是1。因此,通过控制$\lambda$的大小,可以实现对难易样本的选择,当$\lambda$比较小的时候,误差项大于$\lambda$的数据相对较多,这些数据对应的$v$会比较小,即,哪些$v$比较大的数据被入选到本轮训练,这些数据具有较小的误差,也就是一些easy to learn的样本。
对于主动学习部分的权重,文章假设本次都通过Active Learning选择出了最具有代表性的样本,那么无标签数据和标签数据的分布应该会很相似的,所以本文通过Maximum Mean Discrepancy(MMD)的方式,在kernel空间下来比较两个分布,期望这两个分布相似,也就对应了公式中的$\mu$那一坨。
2. 课程学习算法
前面说了一堆的原理,从感性的层面介绍了课程学习本身。下面开始就比较传统的CL算法进行介绍,分为以下几个小类。
- Vanilla CL:第一版的课程学习,引出的这个概念。课程生成和顺序都是人工预先给定的,知识的迁徙是通过模型增量训练的方式实现
- Self-paced Learning:旨在训练模型的时候,同时学习训练数据的顺序
- Balanced CL:除了考虑难易程度以外,还考虑了数据多样性
- Self-paced CL:结合SPL与CL
- Teacher-Student CL:teacher用来判断数据重要性,student来学习task本身
- Progressive CL:不在数据上做文章,而是考虑task从容易到困难的学习(progressive mutation of task)
2.1 Vanilla CL
原始的课程学习,最初由09年Bengio提出,认为模型训练的时候,应该先训练简单的数据,然后不断的提升数据复杂度。这里对数据的简单与复杂的判断是预先给定的,属于priori rule。这些先验规则由人工给定,比如在训练Language Model的时候,从短文本开始训练,后期不断增加文档长度;或者在学习几何形状的时候,从简单的形状开始学习(比如正三角形,正方形,圆形),再到复杂形状(椭圆,矩形,任意三角形)。

参考文献:
- 【ICML 09】Curriculum Learning
- 【NIPS 09】Baby Steps: How “Less is More” in Unsupervised Dependency Parsing
2.2 Self-paced Learning
自步学习是一个很大的方向,本文仅做简单介绍。SPL旨在训练模型的时候,同时学习训练数据的顺序,这里的顺序是通过给样本赋予不同权重来实现的。这里的权重值一般是通过数据似然或者分类误差来设置。考虑一下的优化问题:
\[(w_{t+1}, v_{t+1}) = argmin_{w,v} r(w)+\sum_{t=1}^n v_if(x_i,y_i;w) - \frac{1}{k}\sum_{t=1}^nv_i\]其中,$v$衡量了数据的难易程度,当 $f > \frac{1}{k}$,$v$的最优解是0,反正,当$f < \frac{1}{k}$,$v$的最优解是1。当$k$取很大的值时,只有很少的$f$会入选,这些$f$对应的数据,是远离决策边界,具有很大的likelihood,是属于easy to learn的样本,反之是hard的。因此,训练的时候,需要在每轮优化迭代中,不断的减小$k$值。
参考文献:
- 【NIPS 2010】self-paced learning for latent variable models
2.3 Balanced CL
Balanced CL算法除了考虑难易程度以外,还考虑了数据多样性,希望在每轮选的样本中,class分布均匀,便于模型均衡的学到各类的信息。比如,可以在优化目标里增加了一个约束条件,限制每次选择的结果里,每个类别都包含,限制每个选出的样本集合中,属于第$i$类的数据至少有一个。
\[|| y_i + 1 ||_0 \ge 1\]参考文献:
- 【ICCV 2015】A Self-paced Multiple-instance Learning Framework for Co-saliency Detection
2.4 Self-paced CL
一般来说,传统的CL是预设好了课程,self-paced learning (SPL)是要一边训练一边学习课程,Self-paced CL算法是合并了一下,设计了一个函数(记为$f$)来控制SPL,而课程学习的先验信息则是通过约束条件控制。如下式所示,$\Phi$表示预设好的课程集。
\[min_{w,v} \sum^n_{i=1} L(y_i,g(x_i,w)) + \lambda f(v)\\ s.t. v \in \Phi\]参考文献:
- 【AAAI 2015】self-paced Curriculum Learning
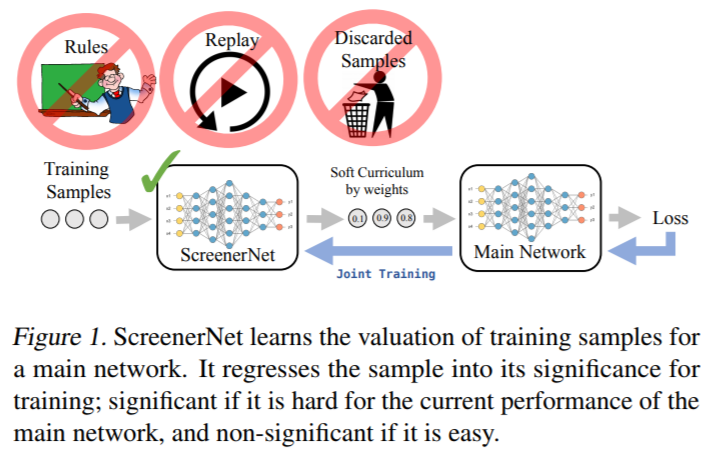
2.5 Teacher-Student CL
Teacher-Student CL模型是基于Teacher-Student架构,传统Teacher-Student假设Teacher是个复杂模型,学习能力强,Student是个简单模型,学习能力相对较弱。Teacher-Student希望在相同输入的情况下,Student能拟合Teacher的输出,达到简化模型的效果,便于模型解释和监控的目的。而Teacher-Student CL模型,将teacher用来判断数据重要性,student结合teacher的信息,并且学习task本身。
| 原理图 | 模型信息流 |
|---|---|
 |
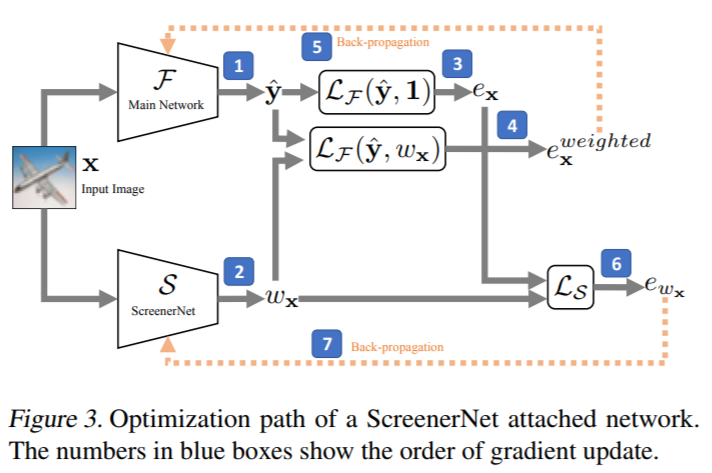 |
因此,Teacher网络(ScreenerNet)的输出是样本重要性$w_{x}$,网络中计算两个loss,一个是加权的loss $e_{x}^{weight}$,一个是未加权的loss $e_{x}$,前者用来更新student网络,后者用来更新teacher网络。teacher网络的loss定义如下,希望让不重要的样本上,error要小,并且要小到有一定的margin gap($M$)
\[\sum_{x \in X} ( (1-w_x)^2 e_x + w_x^2 \max(M-e_x, 0) ) + 其他正则\]参考文献:
- 【arxiv 2018】ScreenerNet
2.6 Progressive CL
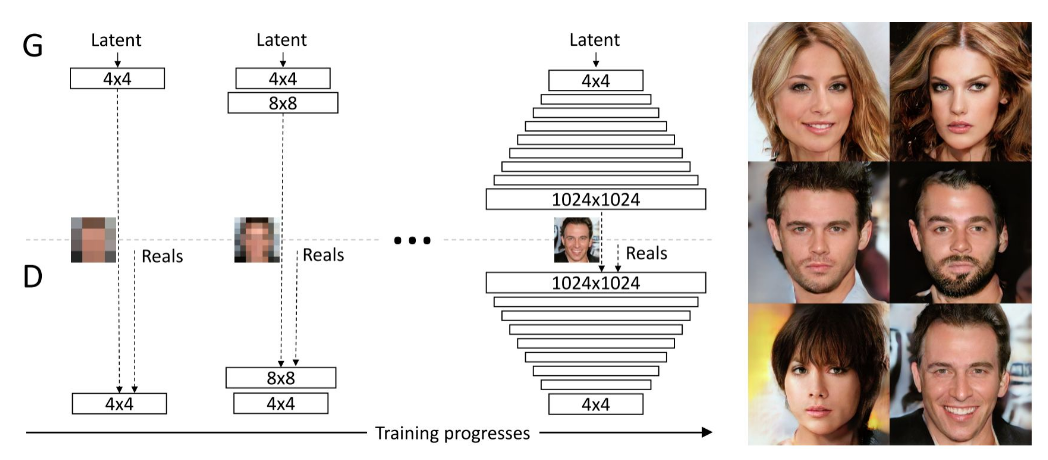
Progressive CL算法考虑task从容易到困难的学习,即考虑模型本身,而不是数据。比如认为任务开始训练的时候,dropout的比例比较应该少一点,到训练后期在增加比例;亦或是在训练GAN的时候,分层训练,先训练复杂度小的GAN,然后慢慢提升模型复杂度
参考文献:
- 【ICCV 2017】Curriculum Dropout
- 【ICLR 2018】Progressive Growing of GAN
3. CL for Reinforcement Learning
强化学习模型的训练一直以难搞出名,对于一些非常难训练的task来说(比如sparse reward),这时候CL可以提供一些 auxiliary task,让Agent慢慢学习到更好,希望用来构造通用性更强,稳定性更强的Agent。所以,有不少工作将CL用来做multi-goals RL,或者用来做exploration。一个超级伟大远景是希望借助CL的思想,实现Agent在简单任务 -> 模拟环境任务 -> 真实环境的任务的质的飞跃(手动滑稽)。那么,具体怎么操作呢?
3.1 What CL Control
在强化学习算法中,可以分为On-policy 和 Off-policy两种,前者算法框架中,学习policy所需的样本是原于该π本身,比如REINFORCE算法,而Off-policy是指从别的策略(叫做behaviour policy)中采样,来更新我们想要的策略(target policy),这种方式最大的好处就在于可以做policy exploration,比如DQN算法。对应这两种RL的算法,CL也有两种迎合方式
- CL for Data Collection
- 一般用在on-policy算法上
- 他可以:
- 影响RL Task的Agent初始状态,初始状态距离终点很近,就是easy task,初始状态距离终点很远,就是hard task
- 影响Reward function,比如,给予探索未知的动作更高的reward,随着探索的增加,未知也越少,task变难;或者,修改达到target的评估标准,一开始要求的accuracy要求很低(投篮,碰着篮板就行),后面慢慢提高(要进球才行)
- 影响Agent Goal,对于multi-goal的setting下,用来制定实现各个goal的顺序,选择优先达实现哪些goal(连续goal和离散goal都可以适用)
- 甚至在一些特殊的场景下(比如,Self-play),用到Opponents的选择上,选择优先和哪个对手进行对抗,比如,选择更有挑战性的对手(measured by winning rate)
- CL for Data Exploitation
- 一般用在off-policy算法上
- 允许在Agent不执行的情况下,mentally experience执行某个动作后的效果,有一点Planning的味道,实现方式一般是在experience replay上做文章,比如,在对replay buffer采样的时候,优先选择一些reward高或者根据信息量的样本(Prioritized experience replay),或者,直接按照从简单到困难的原则,自己构造一些replay buffer。这里的Prioritized experience replay(ICLR 2016)是一个比较有意思的方法,核心思想是从replay buffer里优先选择TD Error大的样本,因为Bellman Equation是想最小化这些误差。这个想法就和SVM的SMO算法一样,贪心的选择最违反KKT条件的支持向量来优化
4. Open Questions
- Task Knowledge Transfer:现在只能判断which task to transfer from,不能做到what to extract and what to transfer。现在不同task之间的knowledge的形式已经写死了,比如通过指定形式的policy,value或者model的参数传递
- Task Generation Automatically:目前还做不到真正全自动生成task,现在要么是假设有一个task pool可供选择,或者,人工给定一些生成task的规则,实现semi-automatic
- Reusing Curricula:CL的训练时间太长,一个Agent要用多个task来训练。能不能做到,一次训练多个Agent,每个都有不同的target task
- Task Generation + Sequencing:怎么结合两个一起做。现在大多数都是分开做的
- Theoretical Results:When and Why CL is useful
- Understanding General Principles for Curriculum Design:可解释性的课程设计