今天组会分享了Hadoop的相关知识点,特此总结一发
1.Hadoop
Hadoop是一个于2011年,由Apache基金会所开发的分布式系统基础架构。它为我们提供了一个可靠的,可扩展的分布式计算框架。总的来说,Hadoop由四部分组成,包括:
- 分布式计算框架MapReduce
- 分布式文件系统HDFS
- 作业调度和资源管理服务YARN
- 用于支持外部组件的公用调用服务Hadoop Common
本文主要就前三部分进行总结。就分布式计算框架而言可以分为模型并行(Model Parallelism),数据并行(Data Parallelism)和两者的混合(Irregular Parallelism)。模型并行化是将模型划分成子模型,分布到各个节点上(比如将线性模型参数W根据feature进行划分);数据并行是将数据划分到不同节点上,而计算模型本身不会进行划分。根据算法迭代方法的不同,现有的分布式计算框架可以划分为基于同步(Synchronization-based)的和基于异步的(Asynchronization-based)。两者的不同在于是否等待所有节点完成计算/任务,然后在进入下一次迭代/任务。
对于Hadoop框架来说,Hadoop是一个基于同步和数据并行(Synchronization-based and Data-distributed)的计算框架。Hadoop是建立在HDFS之上,数据本身已经进行了分布式存储与各个节点上,所以Hadoop的MapReduce计算任务会将整个计算模型/程序发送到各个节点上运行。这暗示着Hadoop不可避免的会涉及到数据在不同节点上的调度,同时带来巨大的IO开销。并且也暗示了MapReduce计算框架不能应用于数据之间有依赖的情况。因为HDFS上的数据是基于IID划分的。另一方面,对于每一次MapReduce任务迭代,MapReduce总是等到所有节点都完成了Map操作之后,再进行Reduce操作。当某个节点执行任务特别慢的时候,整个集群会陷入等待状态。考虑到这个问题Hadoop也做了相应的处理。比如当一定比例的节点完成Map任务的时候,就可以进入Reduce阶段,而不在等待;当然也在从任务调度的层面监控作业进度,将某个节点上执行缓慢的任务放在别的节点上执行。
即便Hadoop本身有一些不足,但是也不影响Hadoop的优势:
- Low cost,搭建Hadoop的成本是很小的,它能利用每一个臭皮匠
- Scalability,多个臭皮匠,顶很多诸葛亮
- Reliability and Fault Tolerance,Hadoop本身提供很多的容错机制,保证集群的可靠性。包括HDFS层面的冗余备份,HA机制对节点宕机的容错,YARN机制对作业调度的容错支持等等。
- Efficiency,分布式计算的优势
- Throughput,支持很大的吞吐量,支持一写多读
当然,Hadoop也有不能处理的场景
- 小数据与大量小文件。由于HDFS上数据是以块(Block)进行存储的,不足块大小的文件同样会占用一个块的大小。如果小文件太多,会占用NameNode过多的内存来维护元数据信息。
- 修改文件的值。HDFS不提供Value-level的数据修改,只能覆写或者追加
- 流式作业和低延时场景。Hadoop MapReduce是操作HDFS上的数据,所以流式数据到来之后,会涉及到在HDFS上的转存操作,然后再是读取数据,交于MapReduce计算。并且MapReduce计算框架本身也会涉及到一些数据溢写的IO操作。因此实时性要求强的场景下,Hadoop并不具有优势
- MapReduce多次迭代。Hadoop对于MapReduce的迭代任务的支持并不友好,需要手动构建多个MapReduce Job。对于众多机器学习算法,算法的迭代是难以避免的。这时候Hadoop不是一个很好的选择
- 基于图的并行计算(Graph parallel computing)。Hadoop是基于数据并行的计算框架,底层HDFS进行数据分布式储存的时候,并没有考虑数据之间的联系,反倒是假设了数据是IID的。因此对于图数据,Hadoop也是不适合的。
2. HDFS
2.1 核心机制
HDFS是Hadoop Distributed File System的缩写,它采用了主从式的结构。根据节点角色的不同,可以主要分为NameNode和DataNode(细分还包括Second Namenode,JournalNode等等)。下图是HDFS的粗略框架
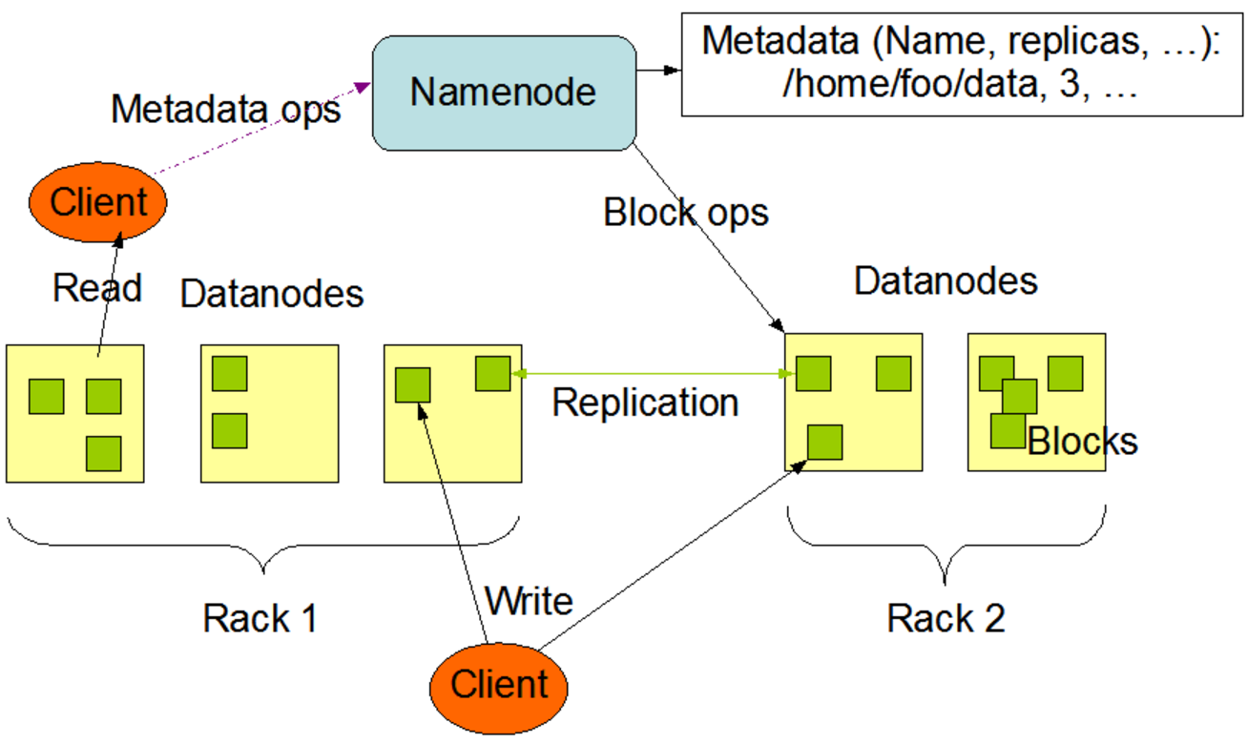
其中
- Namenode充当班长的角色,管理着整个班级(集群)的信息。这份名单被叫做元数据(meta-data)。另外,客户端的访问请求都由namenode负责。另外namenode上也维护了集群的其他信息,包括命名空间,集群配置信息等等。一般来说,namenode上有两个重要文件常驻内存,提供元数据信息。这两个文件是FsImage和EditLogs。前者记录了命名空间,集群配置信息和数据块的相关信息;后者存放了对文件系统的每一次修改记录。比如新建了一个文件夹,修改了数据块的复制个数等等。Namenode需要周期性的合并两个文件,生成新的FsImage文件,以提供客户端的查询访问。
- Datanode负责实际数据的存放,数据以数据块(block)的形式存储在datanode之上,每一个数据块都有多个冗余备份(Replication),以达到容错的作用。客户端对数据的读写操作直接作用在datanode上,但前提是客户端首先得由namenode告知在哪里读,在哪里写。
- 图中的Rack是表示一个PC或者机柜
为了保证整个班级的正常次序,班长需要定期的点名,检查是否有童鞋上课睡觉。这里的namenode并不会主动点名,而是让各个datanode主动汇报,定期的给namenode发送信息。信息包括两部分,心跳检测(HeartBeat)和数据块汇报信息(BlockReport)。前者告诉namenode,datanode还活着;后者是该datanode上数据块的信息。
-
如果HeartBeat和BlockReport被namenode收到了
namenode会汇总大家的blockreport,检测文件的数据块是否有丢失,数据块的复制数是否达到要求。如果没有达到要求,集群会进入Safe Mode。
-
如果namenode超过10min还没有收到某个datanode的HeartBeat
namenode会将这个datanode标记为挂了,然后将原本存储在这个datanode上的数据块,重新复制到其他节点上,并且以后的计算任务也不会再发送给这个datanode了。
当然,班长namenode也可能会挂掉。一旦班长挂了,整个班级都约等于挂了。为了防止这个情况,允许集群的更好的容错能力,Hadoop 1.X启动了副班长策略,引入了Second Namenode。second namenode负责FsImage和EditLog两个文件的合并,减轻namenode的负担(如下图)。
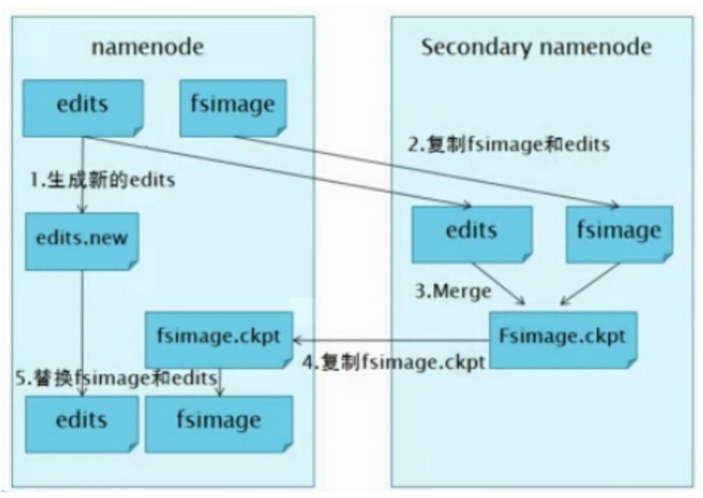
当namenode挂掉了,second namenode上会保存有最新的FsImage文件。那么集群管理狗就可以将这份FsImage拷贝到namenode上,然后人工重启namenode。所以second namenode不提供namenode的故障处理,它仅仅是减轻namenode的压力而已。
要达到故障处理的要求,Hadoop 2.X之后提供了Hadoop HA策略。但是,注意,HA和second namenode策略不能同时使用。Hadoop HA的框架图如下:
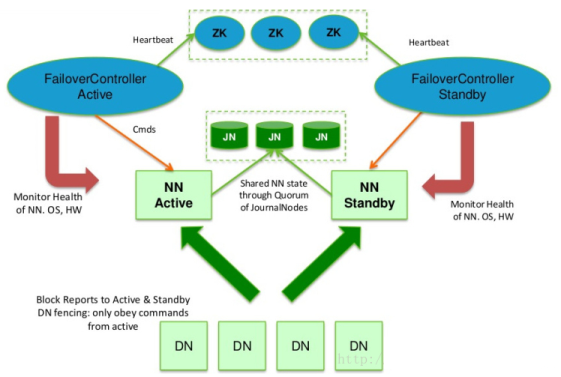
Hadoop HA引入了两个Namenode,即Active Namename和Standby Namenode。但是只有一个提供集群服务,而另一个就standby。一旦active namenode挂了,standby的就立刻上线。至于一开始,哪个namenode充当active的,取决于Zookeeper。Zookeeper提供master选举的作用,这个选举实际上是一个抢占式的锁机制,两个namenode谁先到谁就是active的。
standby namenode需要和active namenode的元信息一致,才能在active one宕掉之后,立刻提供一致服务。为了让元信息一致:
- 集群里的datanode需要同时向两个namenode发送心跳和blockreport;
- active namenode对EditLog的修改需要同时写入JournalNodes(也就是图中的JN)。一般来说,有2N+1台 JN 来存储EditLog,每次写数据操作有大多数(>=N+1)返回成功时即认为该次写成功。同时,也容忍了最多有N台机器挂掉,如果多于N台挂掉,这个算法就失效了。
- 任何修改操作在 Active NN上执行时,JN进程同时也会记录修改log到至少半数以上的JN中,这时 Standby NN 监测到JN 里面的同步log发生变化了会读取 JN 里面的修改log,然后同步到自己的的目录镜像树里面
最后,图中的FailoverController监控了NameNode的状态,并且通过心跳机制,监控自己在zookeeper中的状态。一旦active namenode挂了,则触发standby的namenode上线。
Hadoop HA机制虽然提供了故障处理,但是它任然限制了只能有一个namenode提供服务。并且,如果hdfs中有很多块,那么元数据将占用namenode大量的内存。为了处理这个问题,Hadoop 2.X提供了HDFS Federation机制,它允许多个namenode共用一个集群里的存储资源,每个namenode都可以单独对外提供服务。
2.2 数据存储
在HDFS中,数据是以数据块(Block)的形式存储,不同版本HAdoop的默认块大小不同,128M或者64M。这个值可以用户自己定义。如果一个数据文件被划分成越小的数据块,HDFS读取这个文件时候的并发性也就更高。但是,也意味着将带来更多的磁盘寻道的IO开销,所以这是个trade-off。
HDFS采用了冗余备份的策略,为每一个数据块都保存了多个复制(replicas)。默认replicas的大小为3份。下面展示了HDFS上数据的存储图:
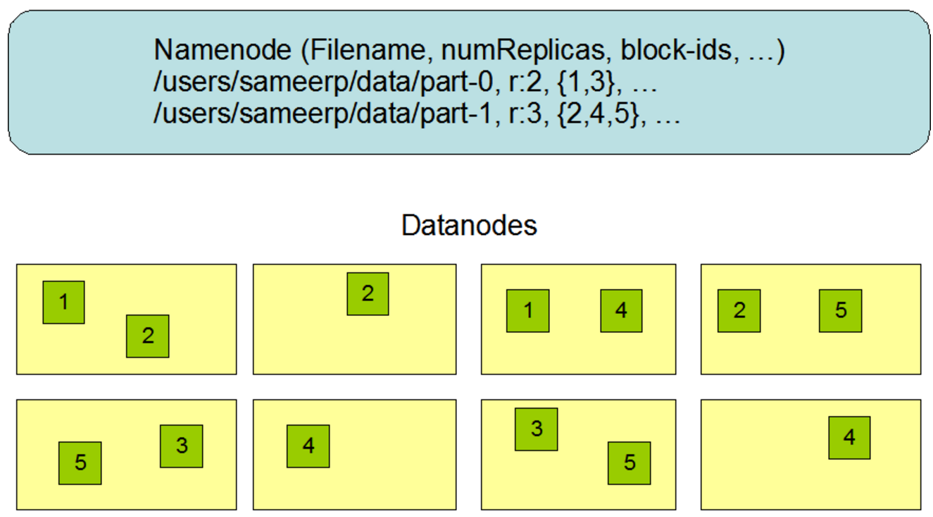
-
图中可以再次看到namenode上存储了文件到数据块的映射信息,比如文件part-0,有两个数据块1,3。每个数据块一共有两个复制,分别存储在不同的节点上。事实上,数据块的总数之间影响了MapReduce过程中,mapper的个数。
-
大文件被划分成了很多的block,而不足block大小的文件(比如一个只有1k的文件),同样占用了一个block。
-
HDFS对文件的划分存储并没有考虑到文件的结构信息。这时候,HDFS引入了InputSplit,InputSplit由用户在读取HDFS数据的时候指定,它保证了一个文件的逻辑划分。比如,下图是一个由4条记录组成的文件,每条记录100M。

假设,HDFS块的大小为128M,那么上面这个文件在HDFS的存储方式可以表示为:
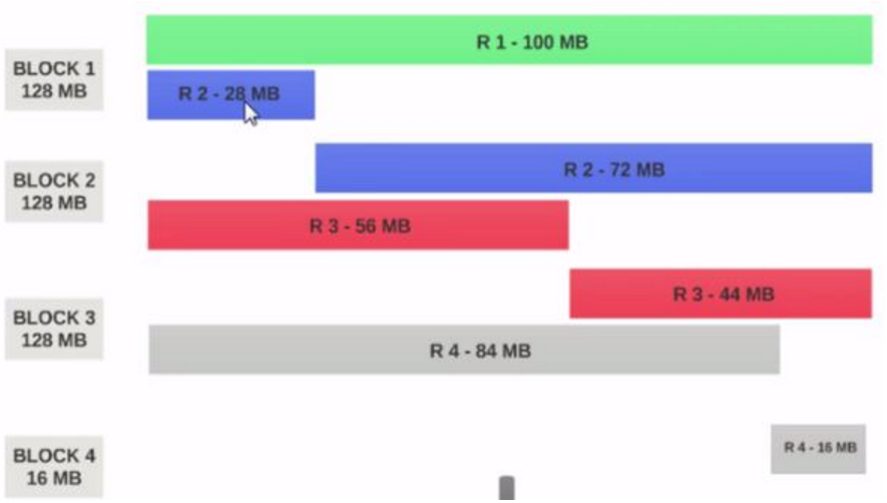
这时候,启动一个mapper来解析任何一个Block都不能都到正确的结果,比较record的结构以及被破坏。为了处理这里问题,我们需要指定一个InputSplit来读取数据,给出每一条record在逻辑上的划分。PS:普通文本文件当然可以不用设置InputSplit。
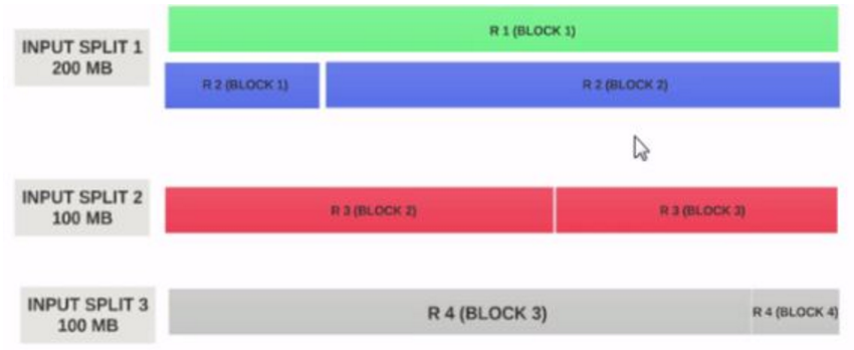
具体来说,需要在设置Job的时候,调用job.setInputFormatClass(WholeFileInputFormat.class)来指定自己实现的InputSplit格式。这里的WholeFileInputFormat.class是自己实现的类,用来指定split,它需要继承FileInputFormat类(当然选择TextInputFormat,SequenceFileInputFormat等等类来集成也是可以的,具体场景,具体分析),覆写createRecordReader和isSplitable方法。同时还要指定自己的RecordReader。下面是一个小栗子,用于解析一个二进制文件。
public class WholeFileInputFormat extends FileInputFormat<Text, BytesWritable> { @Override public RecordReader<Text, BytesWritable> createRecordReader( InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException { //这个类告诉程序要怎么去读文件,找出正确的input划分 WholeFileRecordReader recordReader = new WholeFileRecordReader(); recordReader.initialize(split,context); return recordReader; } @Override protected boolean isSplitable(JobContext context, Path filename) { return false; } }public class WholeFileRecordReader extends RecordReader<Text, BytesWritable> { private FileSplit fileSplit; private FSDataInputStream fin; private Text key = new Text(); private BytesWritable value = new BytesWritable(); private boolean processed = false; private Configuration conf; private String fileName; private int count=0; @Override public void initialize(InputSplit inputSplit, TaskAttemptContext context) throws IOException, InterruptedException { //这里整一些初始化的工作 }@Override public boolean nextKeyValue() { // 这个方法里需要实现具体这么解析一条一条的记录,然后将读取结果设置到key和value里 // 期间,有任何解析问题就返回false,否则返回true value = new BytesWritable(info); key.set(count+""); return true; } @Override public float getProgress() throws IOException, InterruptedException { // TODO Auto-generated method stub return processed? fileSplit.getLength():0; } @Override public void close() throws IOException { // TODO Auto-generated method stub //fis.close(); } @Override public Text getCurrentKey() throws IOException, InterruptedException { // TODO Auto-generated method stub return this.key; } @Override public BytesWritable getCurrentValue() throws IOException, InterruptedException { // TODO Auto-generated method stub return this.value; } } ```
在了解了数据是怎么存储了之后,我们再来了解下客户端是如何读写数据的。
-
读数据
由于namenode上存储了datanode和数据块的路径地址,所以,客户端实际读取数据之前,需要访问namenode获取相关信息。而namenode会计算最佳读取的块,然后返回其位置信息给客户端。最后客户端需要根据返回的信息,自己去找datanode读取数据。流程如下图所示。
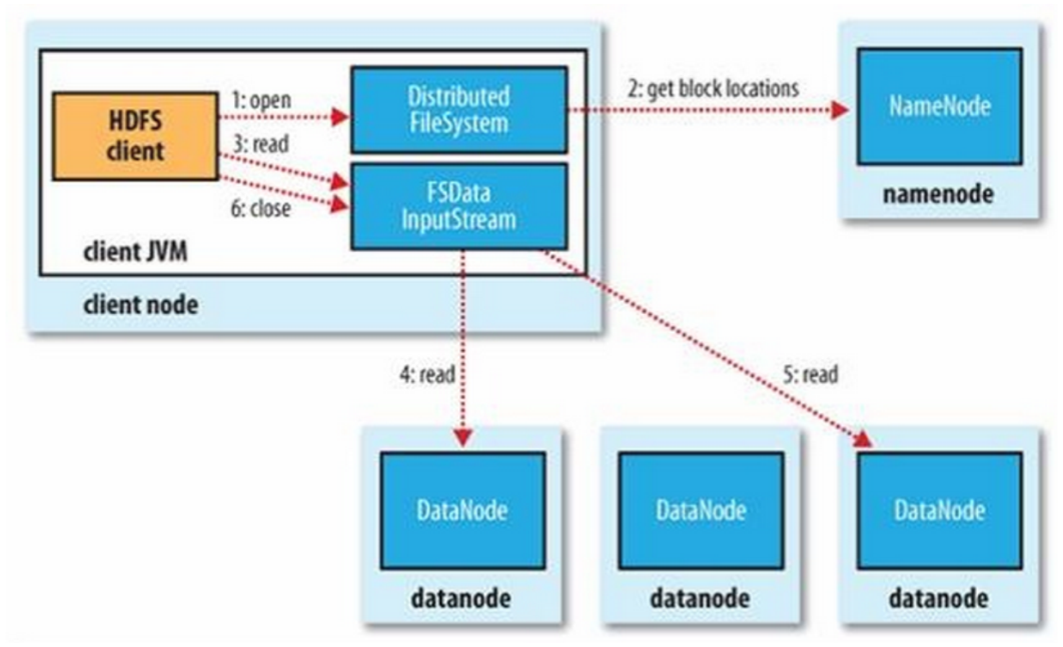
- 客户端(client)用FileSystem的open()函数打开文件
- DistributedFileSystem用RPC调用nameNode,得到文件的数据块信息。对于每一个数据块,namenode节点返回保存数据块的数据节点的地址。DistributedFileSystem返回FSDataInputStream给客户端,用来读取数据。
- 客户端调用stream的read()函数开始读取数据。
- DFSInputStream连接保存此文件第一个数据块的最近的数据节点。Data从数据节点读到客户端(client).
- 当此数据块读取完毕时,DFSInputStream关闭和此数据节点的连接,然后连接此文件下一个数据块的最近的数据节点。
- 当客户端读取完毕数据的时候,调用FSDataInputStream的close函数。在读取数据的过程中,如果客户端在与数据节点通信出现错误,则尝试连接包含此数据块的下一个数据节点。失败的数据节点将被记录,以后不再连接。
幸运的是,客户端具体的程序调用,已经屏蔽了读取数据的细节:
Configuration configuration = new Configuration(); String dataPath = "hdfs://localhost:9000/dml"; FileSystem fileSystem = FileSystem.get(URI.create(dataPath), configuration); FSDataInputStream fsDataInputStream = fileSystem.open(new Path(dataPath)); BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(fsDataInputStream)); String line = bufferedReader.readLine(); while(line != null){ System.out.println(line); line = bufferedReader.readLine(); } bufferedReader.close(); fsDataInputStream.close(); fileSystem.close(); -
写数据
客户端写数据的流程如下所示:
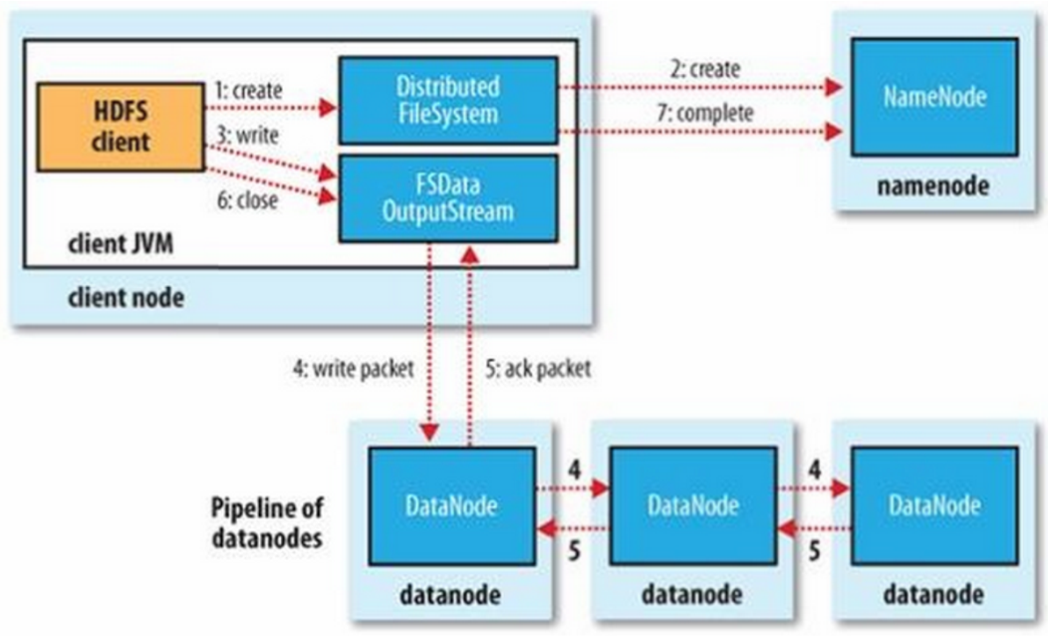
- 客户端调用create()来创建文件
- DistributedFileSystem用RPC调用元数据节点,在文件系统的命名空间中创建一个新的文件。元数据节点首先确定文件原来不存在,并且客户端有创建文件的权限,然后创建新文件。DistributedFileSystem返回DFSOutputStream,客户端用于写数据。
- 客户端开始写入数据,DFSOutputStream将数据分成块,写入data queue。
- Data queue由Data Streamer读取,并通知元数据节点分配数据节点,用来存储数据块(每块默认复制3块)。分配的数据节点放在一个pipeline里。
- Data Streamer将数据块写入pipeline中的第一个数据节点。第一个数据节点将数据块发送给第二个数据节点。第二个数据节点将数据发送给第三个数据节点。DFSOutputStream为发出去的数据块保存了ack queue,等待pipeline中的数据节点告知数据已经写入成功。如果数据节点在写入的过程中失败:关闭pipeline,将ack queue中的数据块放入data queue的开始。当前的数据块在已经写入的数据节点中被元数据节点赋予新的标示,则错误节点重启后能够察觉其数据块是过时的,然后会被删除。失败的数据节点从pipeline中移除,另外的数据块,则写入pipeline中的另外两个数据节点。元数据节点则被通知此数据块是复制块数不足,将来会再创建第三份备份。
- 当客户端结束写入数据,则调用stream的close函数。
- 此操作将所有的数据块写入pipeline中的数据节点,并等待ack queue返回成功。最后通知元数据节点写入完毕。
同样,程序实现:
Configuration configuration = new Configuration(); String dst = "hdfs://localhost:9000/dml"; String data = "data mining lab data mining lab,data mining lab"; FileSystem fileSystem = FileSystem.get(URI.create(dst), configuration); Path path = new Path(dst); FSDataOutputStream fsDataOutputStream = fileSystem.create(path); fsDataOutputStream.write(data.getBytes()); fsDataOutputStream.flush(); fsDataOutputStream.close();
3. YARN & MapReduce
3.1 Yarn
Yarn是Hadoop 2.0以后引入的资源管理系统,它通过资源的动态申请,让Hadoop集群的资源分配变得更加的细致,避免资源浪费(Hadoop 2.0以前map和reducer执行内存是固定的)。Hadoop Yarn一共有三个组成部分:
- 一个ResourceManager:主管整个集群资源的管理和分配;任务调度
- 各个节点上的NodeManager:主管一个节点的资源情况,比如cpu,内存
- 对应一个应用的ApplicationMaster:负责监管某个应用(也就是一个job),以及任务的失败重启
下面是Yarn的框架图:
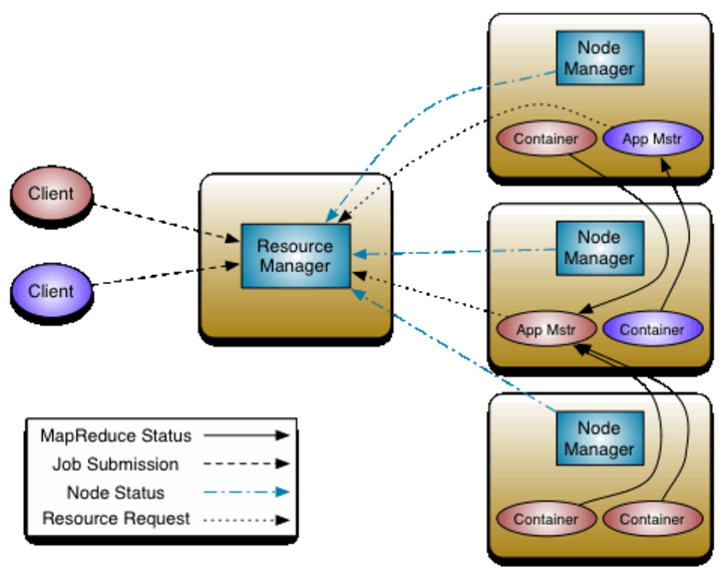
图中有两个client,分别启动了两个applications(看颜色)。一个任务的具体执行者是一个或者多个container,client和container(或者说任务的执行)之间是通过ResourceManager来联系起来的。而ResourceManager通过与Nodemanager的通信,获取每个节点的资源情况,进而掌握整个集群的资源情况。client直接向ResourceManager提交application,而不和具体的worker节点通信。则ResourceManager首先会启动一个applicationmaster,然后该applicationmaster再向resourcemanager申请计算资源,以在更多的节点上开启container进行计算任务。同时,还可以看出,container会向applicationmaster汇报任务的进展情况。
具体来说:
- ResourceManager由两部分组成。用于调度集群里Container的Scheduler 和用于响应client的作业请求,监管applicationmasters的applicationmanager(是的,名字很绕)。在Hadoop中实现的调度器主要有Capacity Scheduler和Fair Scheduler(具体请百度)
- container是具体的执行引擎,计算任务就是跑在它里面。一个application会对于一个或多个container,一个节点上也可以运行多个container。不过container也是一个计算资源(cpu,内存)的抽象封装
- NodeManager掌管节点的cpu,内存,网络等等资源,同时会把这些信息告诉给ResourceManager,以便做资源统计和任务调度
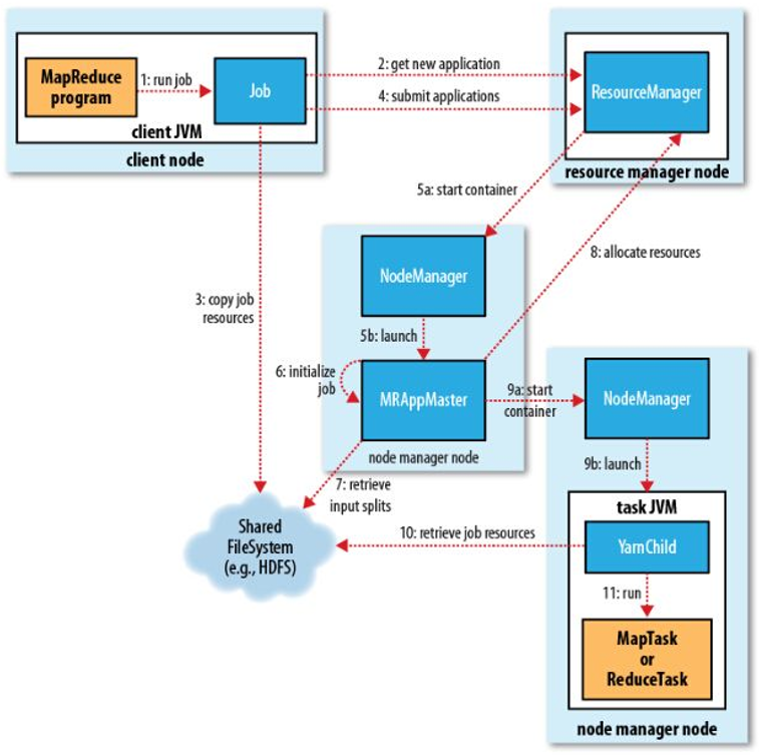
以下面的作业提交流程图为例,看看能不能说得更明白
-
用户通过job.waitForCompletion 方法提交作业
-
首先会与ResourceManager(Applicationmanager)通信,ResourceManager检测application的输入输出设置,作业的输入分片是否能够计算等等,如果有任何问题,将会返回错误信息给client
-
第二步通过之后,便开始上传用户代码jar包和相关文件到HDFS。这一步表明hadoop确实是data-distributed,而不是model-distributed
-
提交作业
-
此时applicationmanager会在一个节点上启动一个container(也就是申请的一些资源),然后在上面运行一个applicationmaster。这个applicationmaster会在applicationmanager上进行注册,并且applicationmanager会监管这个applicationmaster,一旦挂了,就重启他
-
然后applicationmaster开始初始化application,包括创建HDFS目录,生成InputSplit分片信息,获取application的id等等
-
这一步就是根据具体的inputsplit的要求,用于读取输入数据
-
然后applicationmaster向resourcemanager以及nodemanager申请更多的计算资源(container),以准备运行application
-
nodemanager就根据要求,在这些计算资源(container)上,开个子进程,开始执行MapReduce任务,并汇报任务状态给applicationmaster,一旦有container挂了,就重启。等application执行结束,applicationmaster就向applicationmanager注销,释放资源
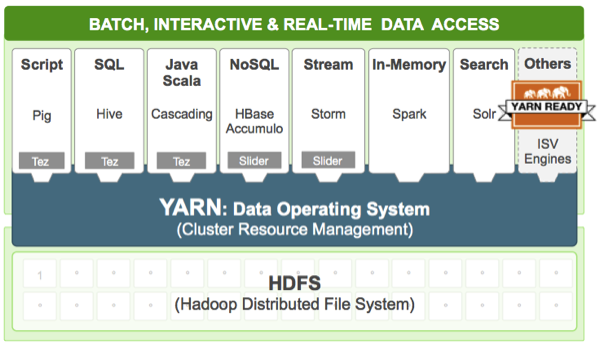
【源于网上】Yarn的另一个目标就是拓展Hadoop,使得它不仅仅可以支持MapReduce计算,还能很方便的管理诸如Hive、Hbase、Pig、Spark/Shark等应用。这种新的架构设计能够使得各种类型的应用运行在Hadoop上面,并通过Yarn从系统层面进行统一的管理,也就是说,有了Yarn,各种应用就可以互不干扰的运行在同一个Hadoop系统中,共享整个集群资源,如下图所示
3.2 MapReduce
提交作业之后,终于我们迎来了算法的执行步骤,也就是老生常谈的MapReduce阶段。总的来说作业的执行代码分为以下三个大部分,每个部分用户都是可以覆写的:
- Setup Task:这是作业初始化所用的标志性任务,它会执行一些很简单的作业初始化工作,只会执行一次。
- MapReduce Task:MapReduce处理数据阶段
- Cleanup Task:作业结束的标志性任务,主要是做一些作业清理的工作,比如删除作业在运行中产生的一些零食目录和数据等信息。
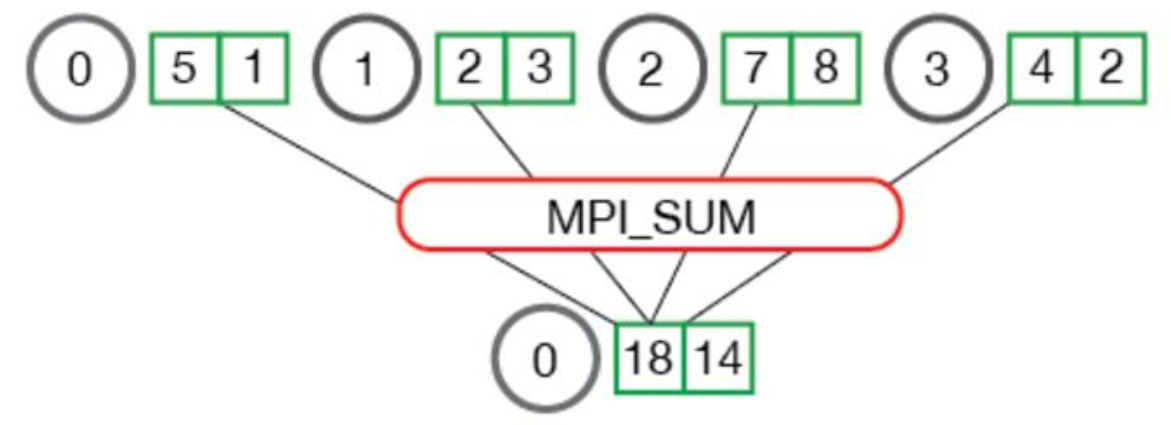
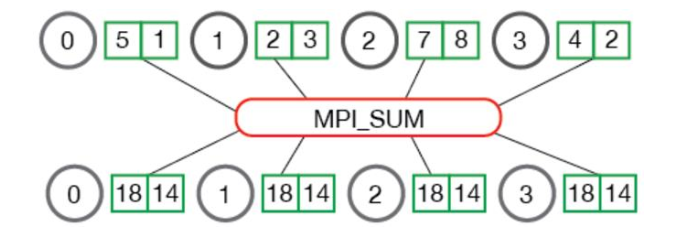
本文主要就MapReduce的详细过程进行分析。MapReduce是一种建立在键值对上的分布式计算编程模型(所谓的键值对就是一个key-value pair)。往大了说,主要是两部分Map和Reduce,更细分一点,便是Map,Reduce和Shuffle。Map就是映射的意思,输入一组键值对,输出另一组键值对。Shuffle是数据分发,是融合key相同的键值对以及分配他们到某个节点上进行执行的过程。Reduce则是规约合一的意思。下图是一个MPI(Message Passing Interface )中Reduce函数的例子,他把四个键值对归一求和。
当然,MPI中还有更厉害的函数,AllReduce。但是他和MapReduce是不一样的。简单的说,AllReduce是Reduce+Broadcast。如下图所示,他把reduce的结果再广播到了其他节点上去。
回到正题,下面是MapReduce中经典的例子:Word Count。这里的splitting不是键值对的形式?其实MapReduce框架在读文件的时候,会把行号作为key,数据行的内容作为value。
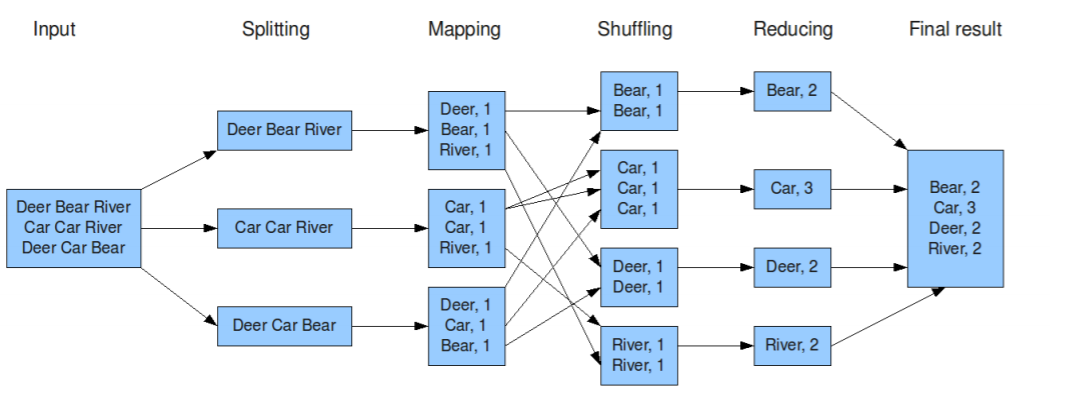
下图是很经典的MapReduce流程图:
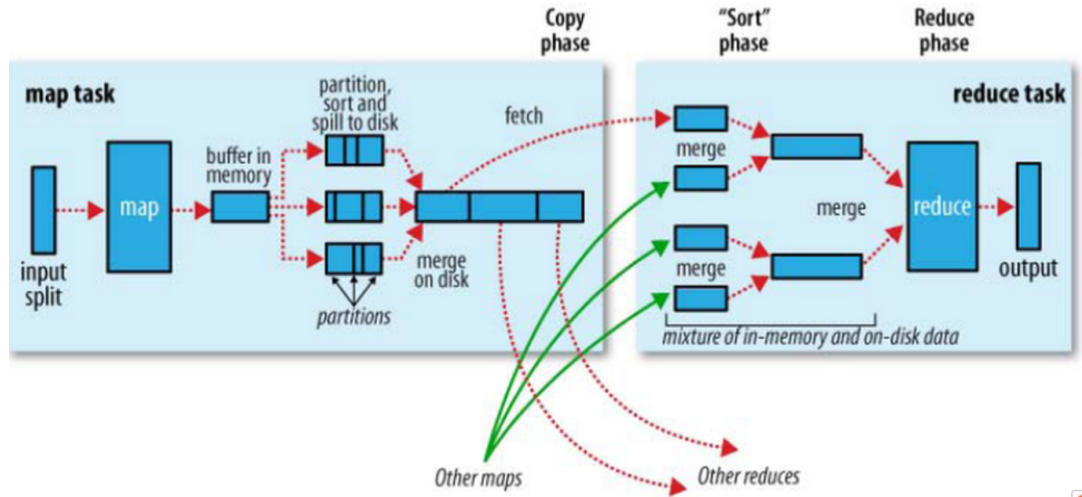
首先是map端做的事情
- 数据切片:在map task执行时,它的输入数据来源于HDFS的block。在前文里,我们已经介绍了InputSplit的概念。map task 读取split。Split与block的对应关系可能是多对一,默认是一对一。
- 结果分区:在经过mapper的运行后,我们得到一组键值对(key,value),而对特定的(key,value)交给哪个reduce task处理,默认是对key hash后再以reduce task数量取模(即放在第(key % numReduce)个reduce上执行)。默认的取模方式只是为了平均reduce的处理能力,如果用户自己对Partitioner有需求,可以订制并设置到job上。分区之后要写入一个数据缓存区,写入之前(key,value)对会被序列化成字节数组。
- 数据溢写:Map端有一个环形的数据缓冲区。数据的缓存区默认100M。当占用达到80M的时候,就有个线程开始把缓冲区内容写入磁盘,剩余20M可以继续写入map的输出。为了减少。但写入过程中第一我们要进行根据key进行排序,第二可以进行Combiner (减少输出文件大小)将有相同key的key/value对进行处理,减少溢写到磁盘的数据量。Combiner会优化MapReduce的中间结果,所以它在整个模型中会多次使用。那哪些场景才能使用Combiner呢?从这里分析,Combiner的输出是Reducer的输入,Combiner绝不能改变最终的计算结果。所以Combiner只应该用于那种Reduce的输入key/value与Combiner输出key/value类型完全一致,且不影响最终结果的场景。比如累加,最大值等。Combiner的使用一定得慎重,如果用好,它对job执行效率有帮助,反之会影响reduce的最终结果。
- 每次溢写都会生成一个溢写文件,最后我们需要把多个溢写文件进行merge成一个,merge过程同样会用到combiner,因为多个溢写文件可能是存在相同key的。
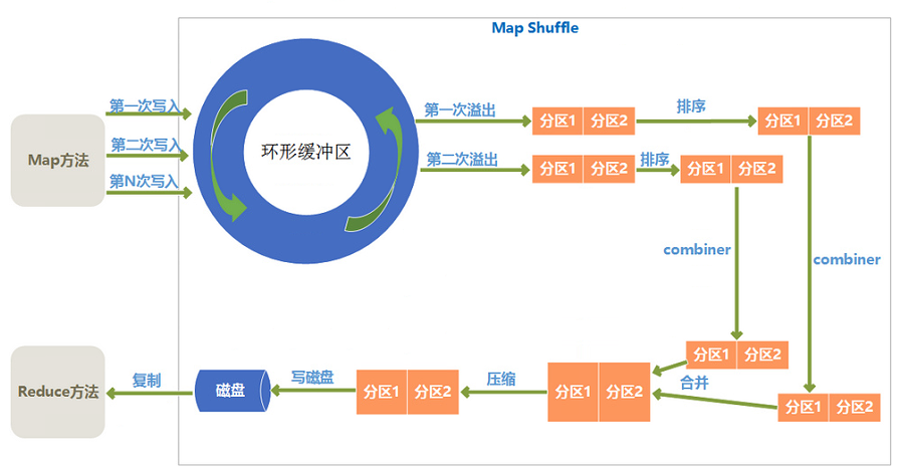
实际上,上面的流程图,从Map操作输出开始就进入了Shuffle阶段。Shuffle阶段分为Map shuffle和Reduce Shuffle。下图给出了Map shuffle的流程,他主要用于融合Map输出和中间结果传输(给reduce)。
接下来是Reduce端的执行,简单地说,reduce task在执行之前的工作就是不断地拉取当前job里每个map task的最终结果,然后对从不同地方拉取过来的数据不断地做merge,也最终形成一个文件作为reduce task的输入文件,执行Reduce计算。 下图先给出Reduce端的Shuffle流程图:
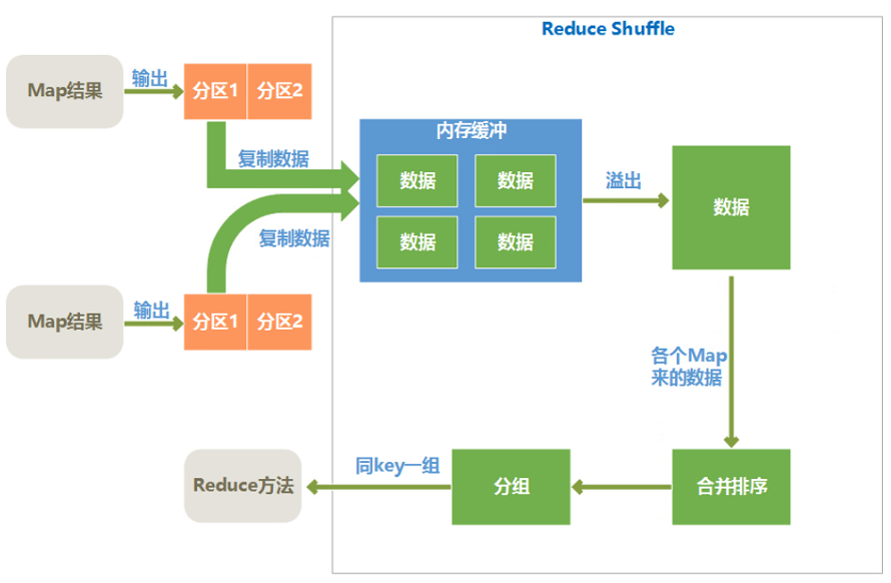
- copy过程,简单地拉取数据。Reduce进程启动一些数据copy线程(Fetcher),通过HTTP方式请求map task所在的TaskTracker获取map task的输出文件。因为map task早已结束,这些文件就归TaskTracker管理在本地磁盘中。
- 合并, 这里的merge如map端的merge动作,Copy过来的数据会先放入内存缓冲区中,这里的缓冲区大小要比map端的更为灵活,它基于JVM的heap size设置,因为Shuffle阶段Reducer不运行,所以应该把绝大部分的内存都给Shuffle用。这里需要强调的是,merge有三种形式:1)内存到内存 2)内存到磁盘 3)磁盘到磁盘。但是,默认情况下第一种形式不启用。当内存中的数据量到达一定阈值,就启动内存到磁盘的merge。与map 端类似,这也是溢写的过程,这个过程中如果你设置有Combiner,也是会启用的,然后在磁盘中生成了众多的溢写文件。第二种merge方式一直在运行,直到没有map端的数据时才结束,然后启动第三种磁盘到磁盘的merge方式生成最终的那个文件。
- Reducer的输入文件。不断地merge后,最后会生成一个“最终文件”。为什么加引号?因为这个文件可能存在于磁盘上,也可能存在于内存中。对我们来说,当然希望它存放于内存中,直接作为Reducer的输入,但默认情况下,这个文件是存放于磁盘中的。当Reducer的输入文件已定,整个Shuffle才最终结束。然后就是Reducer执行,把结果放到HDFS上。
总的来说,MApReduce在Shuffle阶段将带来大量的文件溢写和网络IO操作。这个问题,Spark提供了一套基于内存的分布式计算框架,而我们将在之后在进行介绍Spark的相关东东。